La efemeralización de los robots es imprescindible
Translation into Spanish of an interesting article by Eric Jang, a passionate software developper with vast experience in React, Node.js, Spring Boot 2, and both backend and frontend PHP.
 3 November, 2022 Evaluation techniques for robotics.
3 November, 2022 Evaluation techniques for robotics.A translation by Chema, a Spanish translator working for Ibidem Group, a translation agency in Spain
An original text written by Eric Jang, originally published in
https://blog.evjang.com/2021/09/ephemeralization.html
* * *
Hay un subcampo de investigación en robótica llamado “sim-to-real” (sim2real) mediante el cual uno intenta resolver una tarea robótica en simulación y luego hacer que un robot real haga lo mismo en el mundo real. Mi equipo en Google utiliza ampliamente las técnicas de Sim2Real en prácticamente todos los dominios que estudiamos, incluida la locomoción, la navegación y la manipulación. Los argumentos para hacer investigación robótica en simulación son generalmente bien conocidos en la comunidad: más reproducibilidad estadística, menos preocupación por los problemas de seguridad durante el aprendizaje, evitando la complejidad operativa de mantener miles de robots que se desgastan a ritmos diferentes. Sim2Real se utiliza mucho en plataformas de mano cuadrúpeda y de cinco dedos, porque en la actualidad, dicho hardware solo se puede operar unos cientos de pruebas antes de que comience a desgastarse o romperse. Cuando la dinámica del sistema comienza a variar de un episodio a otro, el aprendizaje se vuelve aún más difícil.
En una entrada de blog anterior, también discutí cómo la iteración en la simulación resuelve algunos problemas complicados relacionados con los cambios en el código nuevo que invalidan los datos antiguos. La simulación hace que esto no sea un problema porque es relativamente económico volver a generar su conjunto de datos cada vez que cambia el código.
A pesar de los avances significativos de sim2real en la última década, debo confesar que hace tres años, todavía me oponía ideológicamente a hacer investigación robótica en simulación, sobre la base de que deberíamos deleitarnos con la riqueza y complejidad de los datos reales, en lugar de perpetuamente permanecer en las aguas seguras de la simulación.
Siguiendo esas creencias, trabajé en un proyecto de robótica de tres años, donde nuestro equipo evitó la simulación y centró la mayor parte de nuestro tiempo en repetir en el mundo real (mea culpa). Ese proyecto fue un éxito y el documento se presentará en la Conferencia sobre aprendizaje robótico de 2021. Sin embargo, en el proceso, aprendí algunas lecciones duras que revirtieron por completo mi postura sobre la evaluación de políticas sim2real y fuera de línea. Ahora creo que la tecnología de evaluación fuera de línea ya no es opcional si está estudiando robots de propósito general, y he modificado mis flujos de trabajo de investigación para depender mucho más de estos métodos. En esta publicación de blog, describo por qué es tentador para los especialistas en robótica repetir directamente en la vida real y cómo la dificultad de evaluar robots de uso general eventualmente nos obligará a confiar cada vez más en técnicas de evaluación offline, como la simulación.
Dos enfoques de Sim2Real
Voy a suponer que el lector está familiarizado con las técnicas básicas de sim2real. De lo contrario, debería consultar este sitio web del taller RSS’2020 para ver videos tutoriales. En términos generales, hay dos formas de formalizar problemas sim2real.
Un enfoque es crear un “adaptador” que transforme las lecturas simuladas de los sensores para que se parezcan lo más posible a los datos reales, de modo que un robot entrenado en simulación se comporte de manera indistinguible tanto en la simulación como en la realidad. Los avances en las técnicas de modelado generativo, como las GAN, han permitido que esto funcione incluso con imágenes naturales.
Otra formulación del problema sim2real es entrenar robots simulados bajo muchas condiciones aleatorias. Al volverse robusta bajo condiciones variadas, la política simulada puede tratar el mundo real como una instancia más bajo la distribución de entrenamiento. Dactyl de OpenAI adoptó este enfoque de “aleatorización de dominios” y pudo hacer que el robot manipulara un cubo de Rubik sin tener que aprender políticas sobre datos reales.
Tanto el enfoque de adaptación de dominio como el de aleatorización de dominio en la práctica arrojan resultados similares cuando se transfieren a la realidad, por lo que sus diferencias técnicas no son muy importantes. La conclusión es que la política se aprende y evalúa en datos simulados, luego se implementa en la realidad con los dedos cruzados.
Ensayar directamente en el mundo real
Hace tres años, mis principales argumentos en contra de la simulación estaban relacionados con la riqueza de datos disponibles para los robots reales frente a los simulados:
- La realidad es desordenada y complicada. Se necesita un mantenimiento regular y un esfuerzo para mantener la limpieza de un escritorio, un dormitorio o un apartamento. Mientras tanto, las simulaciones de robots tienden a ser ordenadas y estériles por defecto, sin mucho “desorden”. En la simulación, debe realizar un trabajo adicional para aumentar el desorden, mientras que en el mundo real, la entropía aumenta de forma gratuita . Esto actúa como una función forzada para que los especialistas en robótica se concentren en los métodos escalables que pueden manejar la complejidad del mundo real.
- Algunas cosas son intrínsecamente difíciles de simular: en el mundo real, puede hacer que los robots interactúen con todo tipo de juguetes blandos y objetos y herramientas articulados. Llevar esos objetos a una simulación es increíblemente difícil. Incluso si uno usa tecnología de fotogrametría para escanear objetos, aún necesita colocar objetos en la escena para hacer que un mundo virtual se parezca a uno real. Mientras tanto, en el mundo real, uno puede recopilar datos ricos y diversos simplemente agarrando el objeto doméstico más cercano, sin necesidad de codificación.
- Cerrar la “brecha de la realidad” es un problema de investigación difícil (que a menudo requiere entrenar modelos generativos de alta dimensión), y es difícil saber si estos modelos están ayudando hasta que uno está ejecutando políticas de robots reales en el mundo real de todos modos. Se sintió más pragmático enfocarse en el aprendizaje de políticas directas en el entorno de prueba, donde uno no tiene que preguntarse si su distribución de capacitación difiere de su distribución de prueba.
Para poner esas creencias en contexto, en ese momento, acababa de terminar de trabajar en Grasp2Vec y Time-Contrastive-Networks., los cuales aprovecharon abundantes datos del mundo real para aprender representaciones interesantes. Lo bueno de estos documentos fue que podíamos entrenar estos modelos en cualquier objeto (Grasp2Vec) o demostración de video (TCN) que el investigador quisiera mezclar con los datos de entrenamiento y escalar el sistema sin escribir una sola línea de código. Por ejemplo, si desea reunir una demostración teleoperada de un robot que juega con un cubo de Rubik, simplemente necesita comprar un cubo de Rubik en una tienda y colocarlo en el espacio de trabajo del robot. En la simulación, tendría que modelar un equivalente simulado de un cubo de rubik que gire y gire como uno real; esto puede ser un esfuerzo de varias semanas solo para alinear la dinámica física correctamente. No dolió que los modelos “simplemente funcionaran”,
Había dos razones más frívolas por las que no me gustaba sim2real:
Estética: los métodos que aprenden en la simulación a menudo se basan en muletas que solo son posibles en la simulación, no en la realidad. Por ejemplo, usar millones de pruebas con un método de gradiente de políticas en línea (PPO, TRPO) o la capacidad de restablecer la simulación una y otra vez. Como alguien que se inspira en la eficiencia de la muestra de humanos y animales, y que cree en la narrativa de LeCake de usar algoritmos de aprendizaje no supervisados en datos enriquecidos, depender de una “muleta de simulación” para aprender se siente demasiado torpe. Un ser humano no necesita sufrir un accidente fatal para aprender a conducir un automóvil.
Un sesgo de “no verdadero escocés”:Creo que las personas que pasan todo su tiempo iterando en la simulación tienden a olvidar la complejidad operativa del mundo real. A decir verdad, es posible que solo haya tenido envidia de otros que publicaban 3 o 4 artículos al año sobre nuevas ideas en dominios simulados, mientras yo pasaba el tiempo respondiendo preguntas como “¿por qué la pinza se cierra tan lentamente?”
El problema del éxito: evaluación de robots de propósito general
Entonces, ¿cómo es que cambié de opinión? Muchos investigadores en la intersección de ML y Robótica están trabajando hacia el santo grial de los “robots generalistas que pueden hacer cualquier cosa que los humanos les pidan”. Una vez que tienes la base de un sistema de este tipo, comienzas a notar una serie de nuevos problemas de investigación en los que no habías pensado antes, y así es como llegué a darme cuenta de que estaba equivocado acerca de la simulación.
En particular, existe un “problema de éxito”: ¿cómo hacemos para mejorar tales robots generalistas? Si la tasa de éxito es mediana, digamos, 50 %, ¿cómo evaluamos con precisión un sistema que puede generalizarse a miles o millones de condiciones operativas? El sentimiento de júbilo de que un robot real haya aprendido a hacer cientos de cosas, tal vez incluso cosas para las que la gente no los entrenó, se ve rápidamente eclipsado por la incertidumbre y el temor de qué intentar a continuación.
Consideremos, por ejemplo, un robot de cocina generalista, tal vez un humanoide bípedo que uno podría implementar en cualquier cocina doméstica para cocinar cualquier plato, incluida la prueba de café de Wozniak. (Se pide a un robot que entre a un hogar estadounidense standard y descubra cómo hacer café: que busque la máquina de café, localice el café, agregue agua, coja una taza y prepare el café presionando los botones adecuados).
En la investigación, una métrica común que nos gustaría conocer es la tasa de éxito promedio: ¿cuál es la tasa de éxito general del robot al realizar una serie de tareas diferentes en la cocina?
Para estimar esta cantidad, debemos promediar el conjunto de todas las cosas que el robot debe generalizar, muestreando diferentes tareas, diferentes configuraciones iniciales de objetos, diferentes entornos, diferentes condiciones de iluminación, etc.

Para un solo escenario, se necesita una cantidad sustancial de intentos para medir las tasas de éxito con una precisión de un solo dígito:
- http://www.nowozin.net/sebastian/blog/how-to-report-uncertainty.html
- https://towardsdatascience.com/digit-significance-in-machine-learning-dea05dd6b85b
- https://stats.stackexchange.com/questions/322953/number-of-significant-figures-to-report-for-a-confidence-interval
La desviación estándar de un parámetro binomial viene dada por sqrt(P*(1-P)/N), donde P es la media de la muestra y N es el tamaño de la muestra. Si su media empírica de la tasa de éxito es del 50 % con N=5000 muestras, esta ecuación le indica que el error estándar es 0,007. Una forma más intuitiva de entender esto es en términos de un intervalo de confianza: hay una probabilidad epistémica del 95 % de que la verdadera media, que puede no ser exactamente el 50 %, se encuentre dentro del rango [50 – 1,3, 50 + 1,3].
¡5000 pruebas es mucho trabajo! Rara vez los experimentos de robótica reales hacen cerca de 300 o incluso 3000 evaluaciones para medir el éxito de la tarea.
De la publicación de blog de Vincent Vanhoucke, aquí hay una tabla que establece una conexión entre el tamaño de su muestra (en el peor de los casos de p=50 %, que maximiza el error estándar) con la cantidad de dígitos significativos que puede reportar:
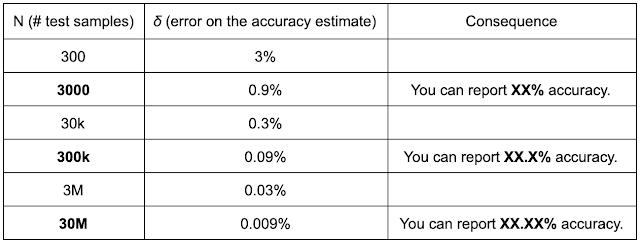
Dependiendo de la duración de la tarea, podría tomar todo día o toda la semana o todo el mes para ejecutar un experimento. Además, hasta que los robots sean lo suficientemente capaces de restablecer sus propios espacios de trabajo, un supervisor humano debe restablecer el espacio de trabajo una y otra vez a medida que se realizan las tareas de evaluación.
Una consecuencia de estos cálculos de servilleta es que empujar la frontera de la capacidad robótica requiere una serie de avances incrementales (por ejemplo, 1% a la vez) con una evaluación extremadamente costosa (5000 episodios por iteración), o una serie de avances verdaderamente cuánticos que son tan grandes de magnitud que se necesitan muy pocas muestras para saber que el resultado es significativo. Pasar de “no funciona en absoluto” a “más o menos funciona” es un ejemplo de un gran salto estadístico, pero en general es difícil sacarlos del sombrero una y otra vez.
Las técnicas como las pruebas A/B pueden ayudar a reducir la varianza de estimar si un modelo es mejor que otro, pero aún no aborda el problema de la complejidad de la muestra de evaluación que crece exponencialmente con la diversidad de condiciones que se espera que generalicen los modelos ML. a.
¿Qué pasa con un estimador imparcial de alta varianza? Un enfoque sería muestrear una ubicación al azar, luego una tarea al azar y luego una configuración de escena inicial al azar, y luego agregar miles de tales ensayos en un solo “estimador de éxito general”. Es difícil trabajar con esto porque no ayuda al investigador a profundizar en problemas en los que aprender bajo un conjunto de condiciones provoca el olvido catastrófico de otro número. Además, si el número de tareas de entrenamiento es muchas veces mayor que el número de muestras de evaluación y los éxitos de las tareas no son independientes, entonces habrá una gran variación en la estimación general del éxito.
¿Qué pasa con la evaluación de robots generales con un estimador sesgado y de baja varianza del éxito general de la tarea? Podríamos entrenar a un robot de cocina para hacer millones de platos, pero solo evaluar en unas pocas condiciones específicas, por ejemplo, midiendo la capacidad del robot para hacer pan de plátano y usándolo como un estimador de su capacidad para realizar todas las demás tareas. El olvido catastrófico sigue siendo un problema: si la tasa de éxito de hacer pan de plátano está inversamente correlacionada con la tasa de éxito de hacer salteados, es posible que esté paralizando el robot de formas que ya no está midiendo. Incluso si eso no es un problema, tener que recopilar 5000 ensayos limita la cantidad de experimentos que uno puede evaluar en un día determinado. Además, terminas con un montón de pan de plátano sobrante.
El siguiente es un consejo profesional, más que una afirmación científica: en general, debe esforzarse por estar en una posición en la que el cuello de botella de su productividad sea la cantidad de ideas que puede generar en un solo día, en lugar de alguna restricción física que te limita a un experimento por día. Esto es cierto en cualquier campo científico, ya sea en biología o robótica.
Lección: La ampliación en realidad es rápida porque requiere poca o ninguna codificación adicional, pero una vez que tiene un sistema que funciona parcialmente, la evaluación empírica cuidadosa en la vida real se vuelve cada vez más difícil a medida que aumenta la generalidad del sistema.
Efemeralización
En su ensayo de 2011 “El software se está comiendo el mundo”, el inversor Marc Andreessen señaló que las empresas de software estaban acaparando cada vez más terreno en la cadena de valor de todos los sectores del mundo. En la década siguiente, Andreesen perfeccionó aún más su idea para señalar que el “Software Eating The World” es la continuación de una tendencia tecnológica, la “efemeralización”, que precede incluso a la era de las computadoras. La Wikipedia dice:
Efemeralización, un término acuñado por R. Buckminster Fuller en 1938, es la capacidad del avance tecnológico para hacer “más y más con menos y menos hasta que finalmente puedas hacer todo con nada”.
De acuerdo con este tema, creo que la solución para escalar la robótica generalista es impulsar la mayor parte posible del ciclo de iteración en el software, de modo que el investigador se libere de la lentitud de tener que iterar en el mundo real.
Andreessen ha planteado la cuestión de cómo podrían cambiar los mercados y las industrias futuras cuando todos tengan acceso a un apalancamiento tan masivo a través de la “computación infinita”. Los investigadores de ML saben que “infinito” es una aproximación generosa: todavía cuesta 12 millones de dólarespara entrenar un modelo de lenguaje de nivel GPT-3. Sin embargo, Andreessen es direccionalmente correcto: deberíamos atrevernos a imaginar un futuro cercano en el que el poder de cómputo sea prácticamente ilimitado para la persona promedio, y dejar que nuestras carreras monten este viento de cola de expansión masiva de cómputo. El apalancamiento informático y de información probablemente siga siendo los recursos de más rápido crecimiento en el mundo.
El software también se está comiendo la investigación. Solía trabajar en un laboratorio de biología en UCSF, donde solo una fracción del tiempo posdoctorado se dedicó a pensar en la ciencia y diseñar experimentos. La mayor parte del tiempo se dedicó a pipetear líquidos en placas de PCR, hacer medios de gel, inocular placas de Petri y, en general, mover líquidos entre tubos de ensayo. Hoy en día, es posible ejecutar una serie de “protocolos biológicos estándar” en la nube, y posiblemente uno podría pasar la mayor parte de su tiempo centrándose en el diseño y análisis de experimentos sofisticados en lugar del trabajo manual.

Imagina un futuro cercano en el que, en lugar de experimentar con ratones reales, podamos simular un modelo de comportamiento de ratón de alta precisión. Si estos modelos son precisos, la ciencia médica experimentará una revolución, ya que los investigadores podrán llevar a cabo estudios a gran escala con miles de millones de modelos de ratones simulados. Con un solo laboratorio, se podría replicar cien años de estudios de comportamiento de ratones prácticamente de un día para otro. Un científico trabajando desde una cafetería con su computadora portátil podría diseñar un medicamento, realizar ensayos clínicos con él a través de servicios en la nube y obtener la aprobación de la FDA, todo desde su portátil. Cuando esto suceda, la predicción de Fuller se hará realidad y realmente parecerá que podemos lograr “todo con nada”.
Efemeralización para robótica
La forma más obvia de hacer efímero el aprendizaje de robots en el software es hacer simulaciones que se parezcan lo más posible a la realidad. Los simuladores no son perfectos: todavía sufren la brecha de la realidad y los problemas de riqueza de datos que originalmente me hicieron escéptico de iterar en la simulación. Pero, después de haber trabajado en robots de propósito general directamente en el mundo real, ahora creo que las personas que deseen tener carreras de alto crecimiento deben buscar activamente flujos de trabajo de gran apalancamiento, incluso si eso significa tener que hacer el trabajo preliminar para realizar una simulación lo más cercana a la realidad.
Puede haber formas de hacer efímera la evaluación robótica sin tener que diseñar minuciosamente a mano los cubos de Rubik y el comportamiento humano en un motor de física. Una solución sería utilizar Machine Learning para aprender de modelos generados a partir de datos y hacer que la política interactúe con el modelo en lugar del mundo real para la evaluación. Si aprender modelos generativos de alta dimensión es demasiado difícil, existen métodos de evaluación fuera de la política y selección de hiperparámetros fuera de línea, métodos que no necesariamente requieren infraestructura de simulación. La intuición básica es que si tiene una función de valor para una buena política, puede usarla para calificar otras políticas en sus conjuntos de datos de validación del mundo real. La desventaja de estos métodos es que, para empezar, a menudo requieren encontrar una buena política o función de valor, y solo son precisos para clasificar las políticas hasta el nivel de la política antes mencionada. La función AQ(s,a) para una política con una tasa de éxito del 70 % puede decirle si su nuevo modelo está funcionando alrededor del 70 % o el 30 %, pero no es eficaz para decirle si obtendrá el 95 % (ya que estos modelos no no sé lo que ellos no saben). Algunas investigaciones preliminares sugiere que la extrapolación puede ser posible, pero aún no se ha demostrado a la escala de evaluación de robots de propósito general en millones de condiciones diferentes.
¿Cuáles son algunas alternativas a los simuladores más realistas? Al igual que el negocio de “laboratorio en la nube”, existen algunos puntos de referencia emergentes alojados en la nube, como AI2Thor y Real Robot Challenge de MPI , donde los investigadores pueden simplemente cargar su código y obtener resultados. El proveedor de la nube de robots maneja todos los aspectos operativos de los robots físicos, lo que libera al investigador para que se concentre en el software.

Un inconveniente de estas configuraciones es que estas plataformas alojadas están diseñadas para experimentos repetibles y reiniciables, y no tienen la diversidad a la que estarían expuestos los robots de propósito general.
Alternativamente, uno podría seguir el enfoque del piloto automático de Tesla e implementar su código de investigación en “modo sombra” en una flota de robots en el mundo real, donde el modelo solo hace predicciones pero no toma decisiones de control. Esto expone la evaluación a datos de gran diversidad que los puntos de referencia de la nube no tienen, pero sufre el problema de la asignación de crédito a largo plazo. ¿Cómo sabemos si una acción predicha es buena o no si el agente no puede realizar esas acciones?
Por estas razones, creo que la simulación realista basada en datos obtiene lo mejor de ambos mundos: obtiene los beneficios de los datos diversos del mundo real y la capacidad de evaluar los resultados simulados a largo plazo. Incluso si depende en gran medida de las evaluaciones del mundo real a través de un laboratorio de robótica en la nube alojado o una flota que ejecuta el Modo Sombra, tener una evaluación complementaria solo de software proporciona una señal adicional que solo puede ayudar a ahorrar costos y tiempo.
Sospecho que un término medio práctico es combinar múltiples señales de métricas fuera de línea para predecir la tasa de éxito: aprovechar la simulación para medir las tasas de éxito, entrenar modelos mundiales o funciones de valor para ayudar a predecir lo que sucederá en “lanzamientos imaginarios”, adaptar imágenes de simulación a realidad -como datos con GAN, y utilizando técnicas de ciencia de datos anticuadas (regresión logística) para estudiar las correlaciones entre estas métricas fuera de línea y el éxito real evaluado. A medida que construimos sistemas de IA más generales que interactúan con el mundo real, predigo que habrá industrias artesanales dedicadas a construir simuladores dedicados a la evaluación sim2real y científicos de datos que construyan modelos personalizados para adivinar el resultado de costosas evaluaciones del mundo real.
La efemeralización reduce los costes de evaluar robots en el mundo real, pero también el coste del propio hardware del robot. Hasta hace poco, los laboratorios de robótica solo podían permitirse un par de brazos robóticos caros de Kuka y Franka. Cada robot costaba cientos de miles de dólares, porque tenían encoders y motores que permitían una precisión de nivel milimétrico. Hoy en día, puedes comprar servos baratos de AliExpress.com por unos pocos cientos de dólares, pegarlos en algunas placas de metal y controlarlos en circuito cerrado usando una cámara web y una red neuronal que se ejecuta en una computadora portátil.
En lugar de confiar en el control de posición preciso del hardware, el brazo se mueve basándose únicamente en la visión y la coordinación ojo-mano. Toda la complejidad se ha migrado del hardware al software (y al aprendizaje automático). Esta tecnología aún no está lo suficientemente madura como para que las fábricas y las empresas automotrices reemplacen sus máquinas de precisión con servos baratos, pero el mensaje es muy claro: el software reemplaza al hardware, y esta tendencia se acelerará cada vez más.
Agradecimientos
Gracias a Karen Yang, Irhum Shafkat, Gary Lai, Jiaying Xu, Casey Chu, Vincent Vanhoucke y Kanishka Rao por revisar los borradores anteriores de este ensayo.