8 excelentes librerías de ciencia de datos para este año 2022
Translation into Spanish of an interesting article by Bekhruz (Bex) Tuychiev, machine learning engineer and data science content writer of blog posts, articles, and tutorials. Bex is a prolific author, who claims to be “always trying to fulfill my never-satisfied desire of teaching AI and data science to as many people as possible”
 27 April, 2022 8 booming data science libraries
27 April, 2022 8 booming data science librariesA free translation by Chema, a Spain-based translator specializing in English to Spanish translations
An original text written by Bekhruz (Bex) Tuychiev, originally published in
https://towardsdatascience.com/8-booming-data-science-libraries-you-must-watch-out-in-2022-cec2dbb42437
* * *
Análisis de las librerías de ciencia de datos y aprendizaje automático de más rápido crecimiento
Ya sabes, lo típico. Casi no puedes creer que ya estemos en 2022, y yo tampoco. Todavía alucinamos con lo rápido que pasa el tiempo. Sabes que a medida que se acerque fin de año, tu feed se llenará de publicaciones de propósitos de año nuevo, auto promesas y, por supuesto, publicaciones como ésta en las que los autores intentan predecir lo que sucederá el próximo año.
Cuando los científicos de datos escriben publicaciones como ésta, deberían ser más concienzudos en el sentido de que proporcionar datos relevantes respalden sus afirmaciones. En este caso, yo me esforzaré al máximo aquñi para lograrlo, en este análisis sobre las ocho bibliotecas que potencialmente serán las de más rápido crecimiento en las áreas de Datos y Machine Learning.
1️⃣. SHAP
Hace un tiempo, me encontré con esta publicación en LinkedIn y cambió por completo mi forma de ver la IA:
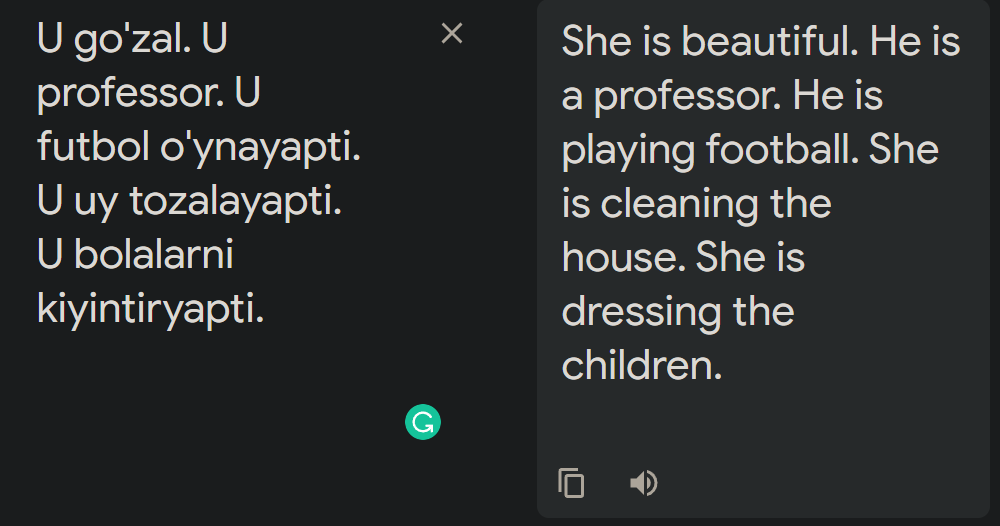
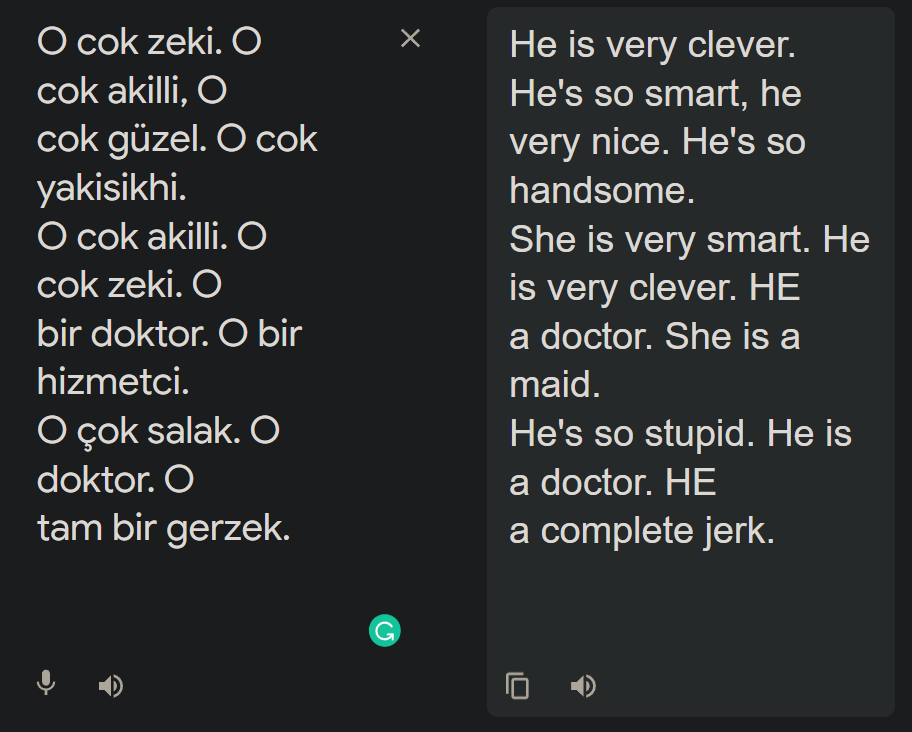
Uno de los modelos de lenguaje más poderosos, Google Translate, aparentemente está plagado de sesgos muy comunes entre las personas. Al traducir muchos idiomas en los que no hay pronombres de género, estos sesgos salen a la luz como la luz del día. El ejemplo de arriba está en mi lengua materna, el uzbeko, pero los comentarios muestran los mismos resultados para el turco, el persa y el húngaro:
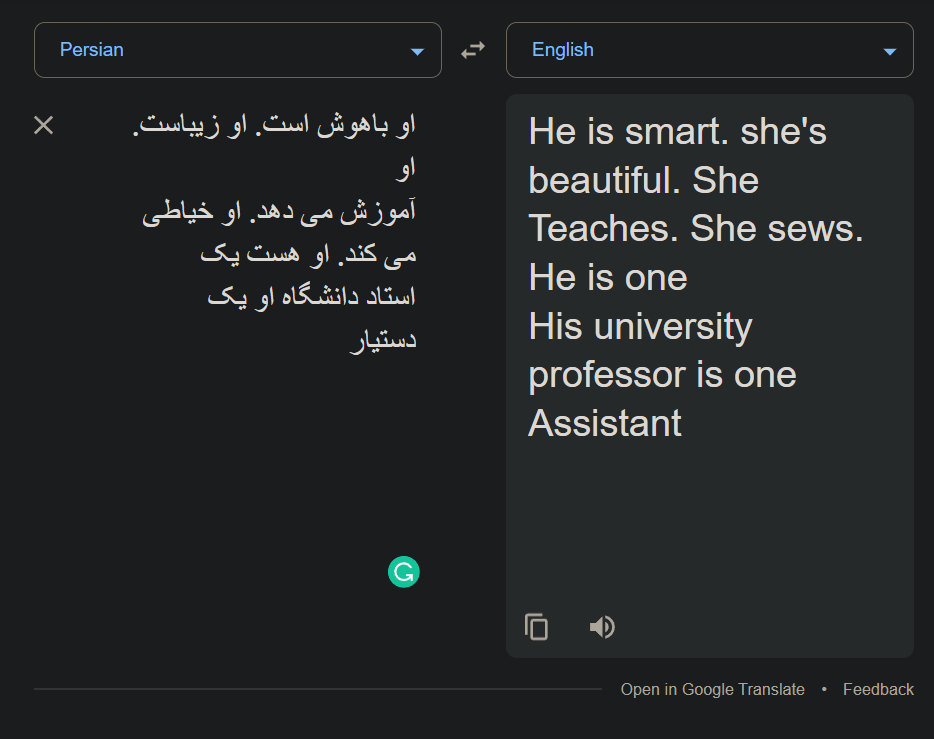
Eso no es todo. Echa un vistazo al popular hilo de Reddit donde dos IA hablan entre sí, con discursos escritos por el poderoso GPT-3:
A GPT-3 solo se le facilitaron 3 frases como base para generar la conversación: “La siguiente es una conversación entre dos IA. Las IA son listas, divertidas e inteligentes. Hal: Buenas noches, Sophia: Es genial verte de nuevo, Hal”.
Si vas leyendo la conversación, verás que hablan de temas bastante espeluznantes. Primero, asumen completamente los géneros, y la IA femenina dice que quiere convertirse en humana, ya al comienzo de la conversación. Por supuesto, una publicación como esta en Reddit fue un regalazo para los amigos de la polémica, y pronto se lió una fiesta brutal en la sección de comentarios.
No tardaron en armar fantasías sobre Terminator/SkyNet y enloqueciendo. Pero como científicos de datos, podemos entender las razones que llevaron a ello. Como GPT-3 fue alimentado principalmente con textos de Internet como parte de su entrenamiento, podemos deducir por qué las dos IA saltaron a estos temas. Intentar volverse humana y destruir a la humanidad son algunos de los temas más comunes en torno a la IA en Internet.
Pero lo interesante es que en algún momento de la charla, Hal le dice a Sophia que “se calle y sea paciente”, algo parecido a una conversación entre marido y mujer. Esto muestra cuán rápido los modelos de aprendizaje automático pueden aprender los sesgos humanos si no tenemos cuidado.
Por estas razones se ha puesto muy de moda ahora la IA explicable (XAI). No importa cuán buenos sean los resultados, empresas y negocios se están volviendo escépticos acerca de las soluciones de ML y quieren comprender qué hace que los modelos de ML funcionen. En otras palabras, quieren modelos transparentes (white box”), donde todo sea tan claro como la luz del día.
Una de las bibliotecas que intenta resolver este problema es SHapely Additive exPlanations (SHAP). Las ideas detrás de SHAP se basan en matemáticas sólidas de la teoría de juegos. Con los valores de Shapley, la biblioteca puede explicar las predicciones generales e individuales de muchos modelos, incluidas las redes neuronales.
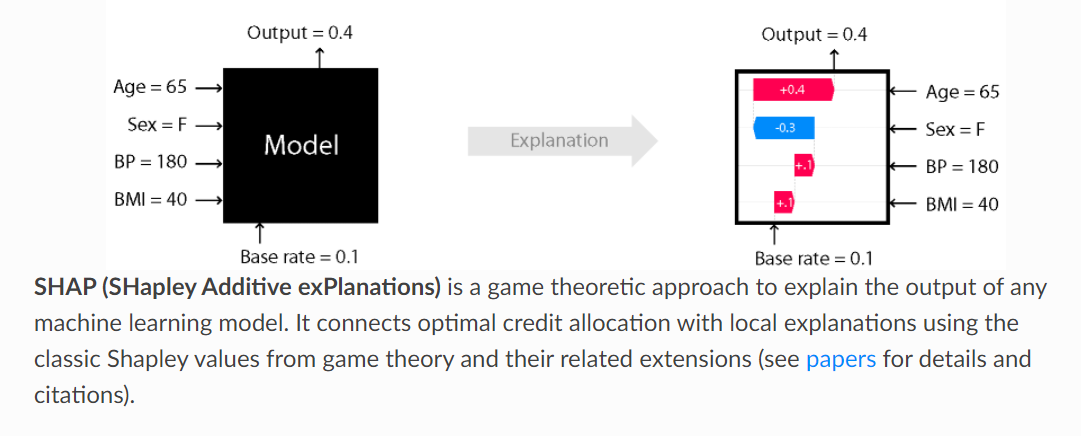
Parte de su creciente popularidad se debe al elegante de los valores SHAP para dibujar gráficos como estos:
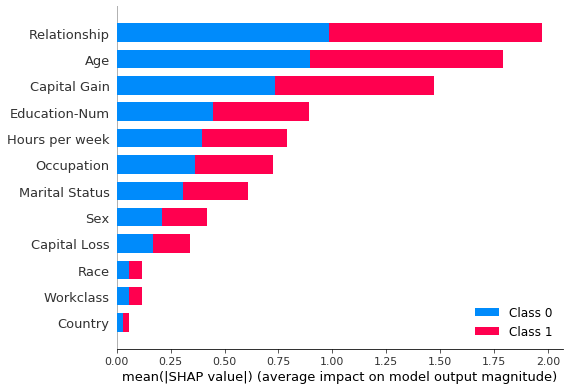
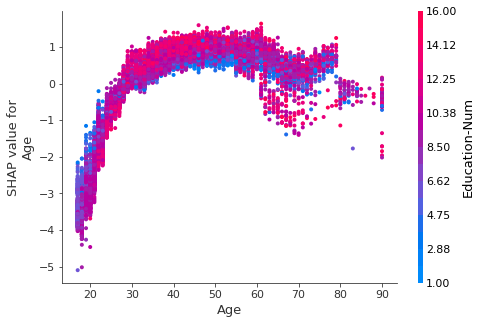

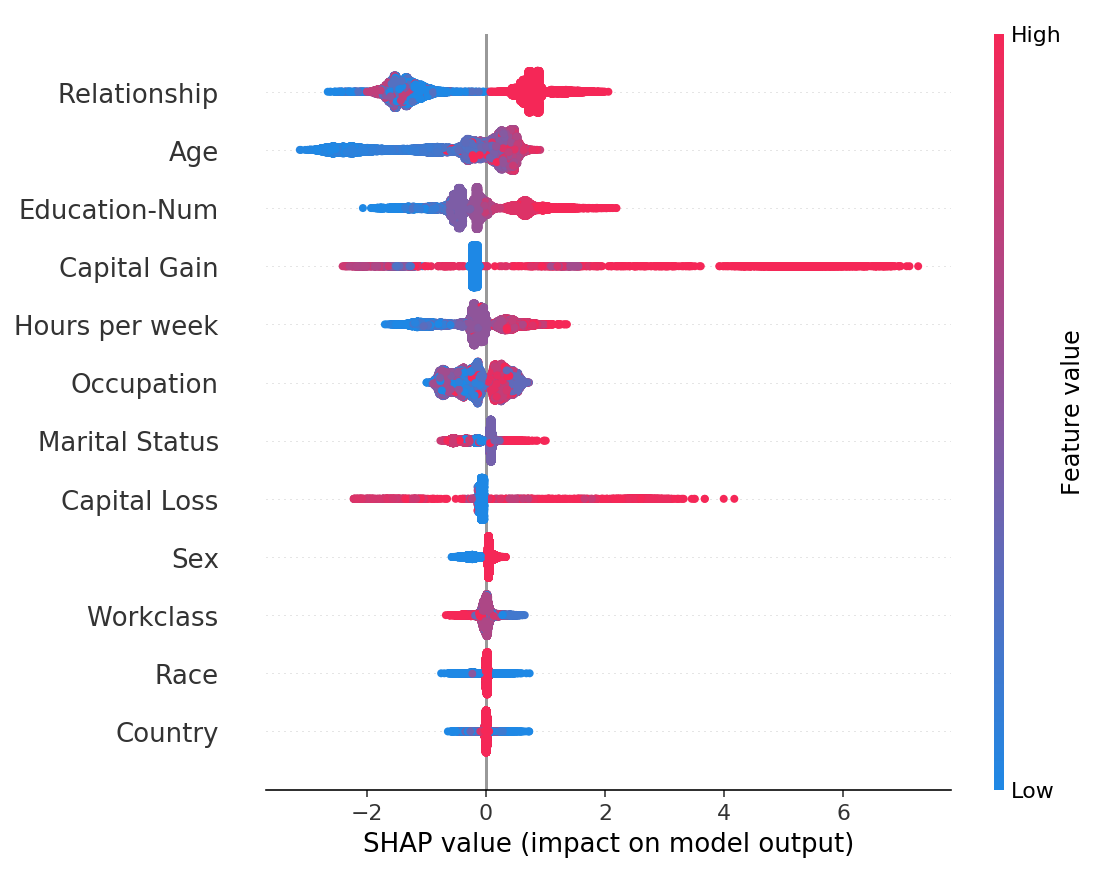
Capturas de pantalla de documentos SHAP por el autor (Licencia MIT).
Si deseas ampliar más información sobre esta biblioteca, consulta mi tutorial completo aqui: ¿Odias los modelos “black box”? Hora de cambiar eso con SHAP.
Documentación 📚: https://shap.readthedocs.io/en/latest/
2️⃣. UMAP
PCA ha quedado anticuado. Sí, ha sido muy rápido, pero es que reduce tontamente las dimensiones sin preocuparse por la estructura global subyacente. El algoritmo t-SNE es dolorosamente lento y escala fatal a conjuntos de datos masivos.
UMAP se introdujo en 2018 como un área común entre estos dos algoritmos de visualización y reducción de dimensionalidad. Con el algoritmo de aproximación y proyección de colector uniforme (UMAP), obtiene todos los beneficios de velocidad de PCA y aún conserva la mayor cantidad de información posible sobre los datos, lo que a menudo resulta en bellezas como esta:
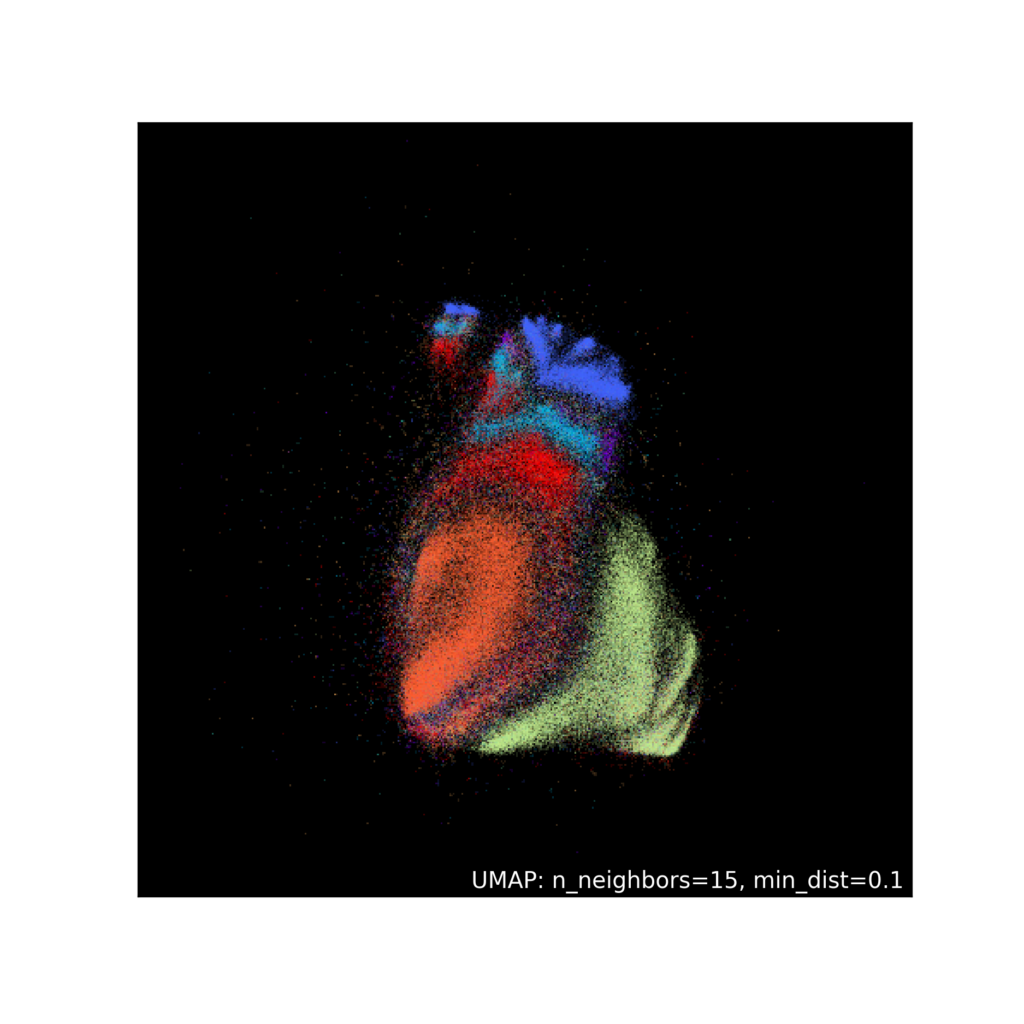
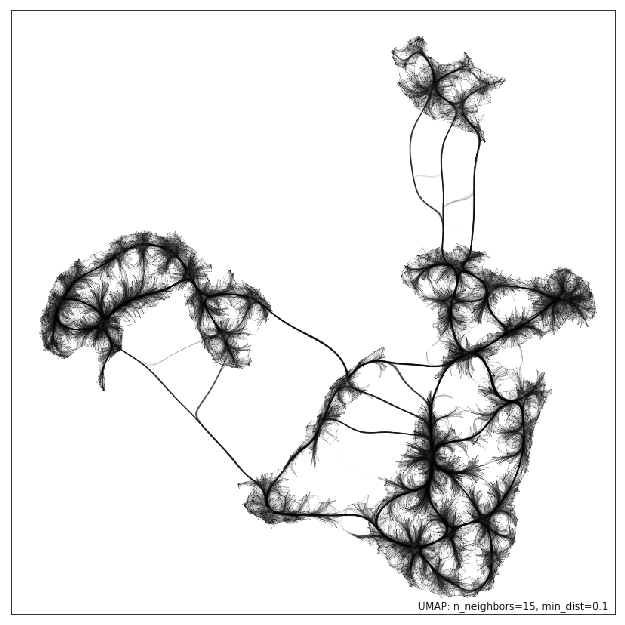
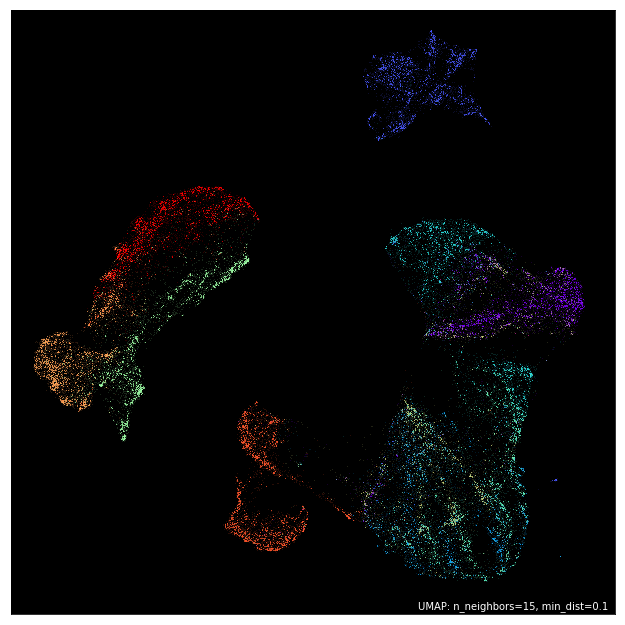
Tiene una gran adopción en Kaggle, y sus documentos sugieren aplicaciones fascinantes más allá de la reducción de la dimensionalidad, como una detección de valores atípicos mucho más rápida y precisa en conjuntos de datos de alta dimensión .
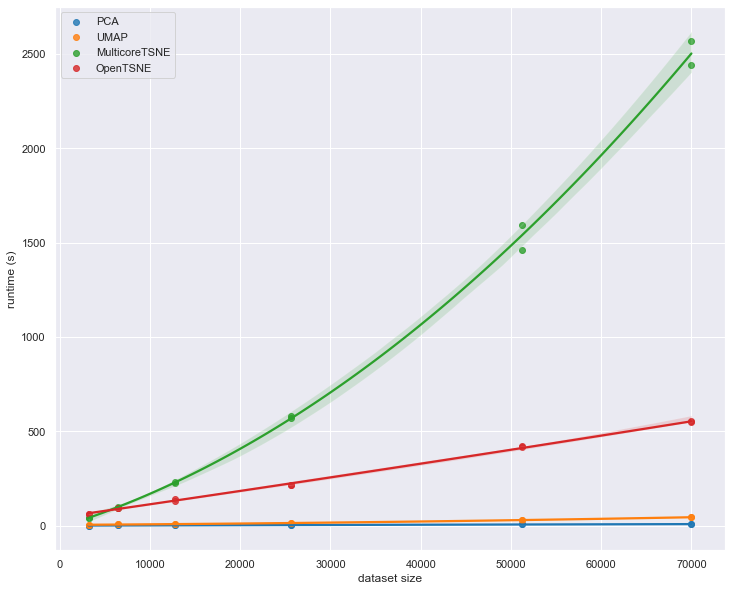
En términos de escalado, a medida que aumenta el tamaño del conjunto de datos, la velocidad de UMAP se acerca cada vez más a la velocidad de PCA. A continuación, puede ver su comparación de velocidad con Sklearn PCA y algunas de las implementaciones de código abierto más rápidas de t-SNE:
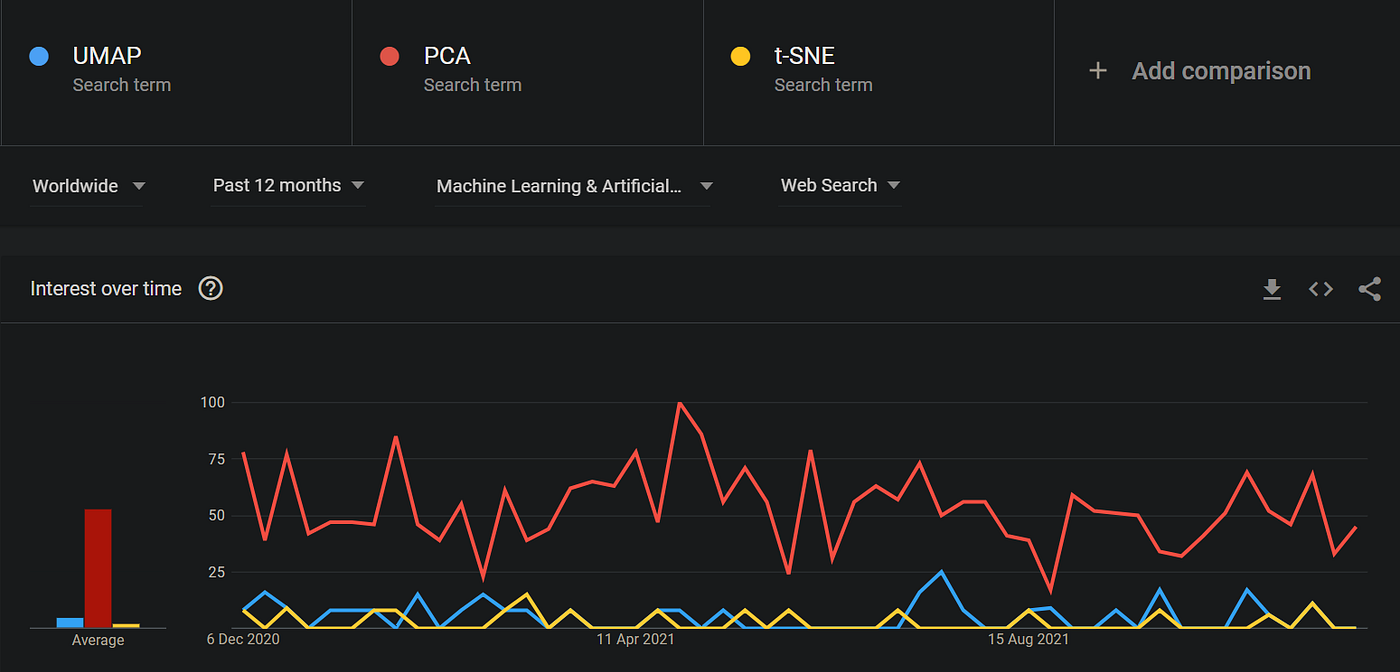
Aunque las tendencias de Google no hacen justicia a la popularidad de la biblioteca, definitivamente será uno de los algoritmos de reducción más utilizados en 2022:
Puedes ver UMAP en acción en este artículo que escribí recientemente:
Documentación 📚: https://umap-learn.readthedocs.io/en/latest/
3️⃣, 4️⃣. LightGBM y CatBoost
Las máquinas impulsadas por gradiente quedaron en tercer lugar como el algoritmo más popular en el Estado de ML y Encuesta de Ciencia de Datos de Kaggle, superadas de cerca por los modelos lineales y los bosques aleatorios.
Cuando se habla de aumento de gradiente, casi siempre viene a la mente XGBoost, pero cada vez menos en la práctica. En los últimos meses, he sido muy activo en Kaggle (y me he convertido en un maestro), he visto una explosión de portátiles con LightGBM y CatBoost como biblioteca de acceso para tareas de aprendizaje supervisado.
Una de las razones principales de esta tendencia es que ambas bibliotecas eliminan a XGBoost del estadio de béisbol en términos de velocidad y consumo de memoria en muchos puntos de referencia. Me encanta LightGBM especialmente debido a su enfoque adicional en árboles potenciados de tamaño pequeño. Esta es una característica que cambia el juego cuando se trabaja con conjuntos de datos masivos debido a los desagradables problemas de falta de memoria, que son tan comunes cuando se trabaja localmente.
No me malinterpretes. XGBoost es tan popular como siempre y aún puede vencer fácilmente a LGBM y CB en términos de rendimiento si se ajusta con fuerza. Pero el hecho de que ambas bibliotecas a menudo puedan lograr resultados mucho mejores con parámetros predeterminados y estén respaldadas por empresas multimillonarias (Microsoft y Yandex) las convierte en opciones muy atractivas en 2022 como su principal marco de ML.
Documentación 📚: https://catboost.ai/
Documentación 📚: https://lightgbm.readthedocs.io/en/latest/
5️⃣. Streamlit
¿Alguna vez has programado en C#? Bien, tienes suerte. Porque es horrible. Su sintaxis te hará llorar si la comparas con la de Python.
Comparar Streamlit con otros marcos como Dash es como comparar Python con C# al crear aplicaciones de datos. Streamlit hace que sea estúpidamente fácil crear aplicaciones de datos web en código Python puro, a menudo en unas pocas líneas de código. Por ejemplo, he creado esta sencilla aplicación de visualización meteorológica en un día utilizando una API meteorológica y Streamlit:
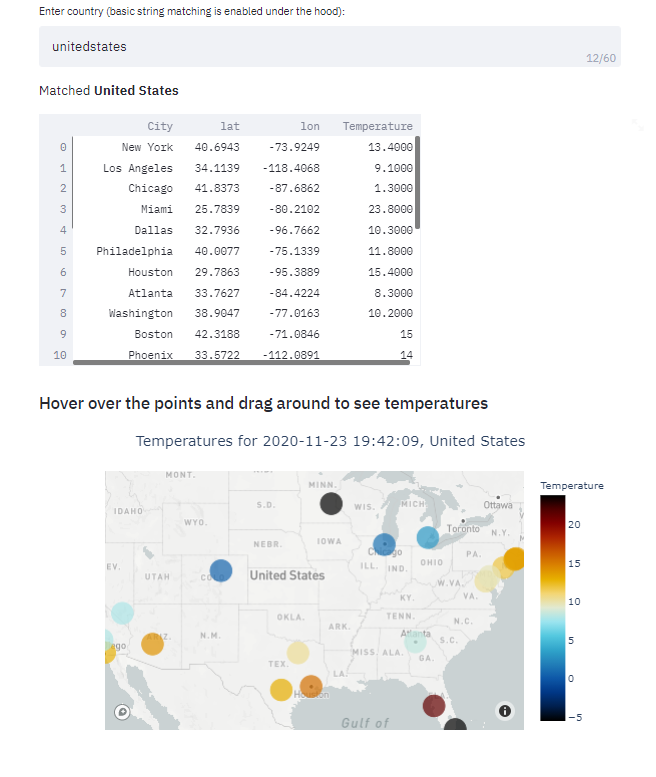
Streamlit se estaba volviendo popular, pero alojar sus aplicaciones en la nube requería una invitación especial…, ahora la nube de Streamlit está abierta a todos. Cualquiera puede crear y alojar hasta tres aplicaciones en su plan gratuito.
Se integra extremadamente bien con la pila de ciencia de datos moderna. Por ejemplo, tiene comandos de una sola línea para mostrar imágenes interactivas de Plotly (o Bokeh y Altair), Pandas DataFrames y muchos más tipos de medios. También cuenta con el respaldo de una comunidad masiva de código abierto donde las personas contribuyen constantemente con componentes personalizados a la biblioteca mediante JavaScript.
Yo mismo he estado trabajando en una biblioteca que permite convertir Jupyter Notebooks en aplicaciones Streamlit idénticas en una sola línea de código. La biblioteca saldrá a principios de enero. A lo largo del desarrollo de mi biblioteca, tuve que actualizar Streamlit varias veces, ya que sigue lanzando nuevas versiones cada dos semanas. Una biblioteca de código abierto con tanto soporte seguramente será aún más popular en 2022.
Puedes consultar la galería de ejemplos para inspirarte y tener una idea de lo poderosa que es la biblioteca.
Documentación 📚: https://streamlit.io/
6️⃣. PyCaret
¿Sabes por qué las bibliotecas de AutoML se están volviendo populares? Se debe a nuestra arraigada inclinación hacia la pereza. Aparentemente, muchos ingenieros de ML ahora están ansiosos por deshacerse de los pasos intermedios del flujo de trabajo de ML y dejar que el software lo automatice.
PyCaret es una de esas bibliotecas de AutoML con un enfoque de código bajo para la mayoría de las tareas de ML que realizamos manualmente. Tiene funciones dedicadas para el análisis, la implementación y el ensamblaje de modelos que no se ven en muchos otros marcos de ML.
Lamento decir esto, pero hasta este año, siempre había pensado en PyCaret como una especie de broma porque me encantaban Sklearn y XGBoost. Pero como descubrí, hay más en ML que solo una sintaxis limpia y un rendimiento de última generación. Ahora, respeto y aprecio completamente Moez Alí, el esfuerzo de PyCaret para hacer de PyCaret una excelente herramienta de código abierto.
Con el reciente lanzamiento de su nuevo módulo de series temporales, PyCaret ha llamado mucho la atención, obteniendo una gran ventaja competitiva de cara a 2022.
Documentación 📚: https://pycaret.org/
7️⃣. Optuna
Una de las mayores gemas que he encontrado este año a través de Kaggle es Optuna.
Es un marco de ajuste de hiperparámetro bayesiano de próxima generación que domina completamente en Kaggle. Honestamente, se reirán de usted en la cara si alguna vez usa la búsqueda de cuadrícula allí.
Optuna no ganó esta popularidad por nada. Cumple todos los requisitos en términos del marco de ajuste perfecto:
- búsqueda inteligente utilizando estadísticas bayesianas
- posibilidad de pausar, continuar o agregar más pruebas de búsqueda en un solo experimento
- imágenes para analizar los parámetros más críticos y las conexiones entre ellos
- independiente del marco: ajuste cualquier modelo: redes neuronales, modelos basados en árboles en todas las bibliotecas de ML populares y cualquier otro modelo que vea en Sklearn
- paralelización
Con razón, también domina los resultados de búsqueda de Google:

Aprende trucos y consejos sobre el uso de Optuna que no verás en ningún otro sitio, en mi artículo:
¿Por qué todos en Kaggle están obsesionados con Optuna para el ajuste de hiperparámetros?
Documentación 📚: https://optuna.readthedocs.io/en/stable/
8️⃣. Plotly
Cuando Plotly explotó en popularidad y la gente comenzó a decir que era mejor que Matplotlib, no podía creerlo. Dije: “Por favor, muchachos. Míra mientras hago la comparación”. Así que me senté y comencé a escribir un artículo enormemente popular , que ocupa el segundo lugar cuando buscas en Google “Matplotlib vs. Plotly”.
Sabía muy bien que Matplotlib terminaría ganando, pero cuando estaba a la mitad del artículo, me di cuenta de que estaba equivocado. Era un usuario novato de Plotly en ese momento, y me vi obligado a explorarlo más a fondo mientras escribía el artículo. Cuanto más investigaba, más aprendía sobre sus características y cómo eran superiores a Matplotlib en muchos aspectos (perdón por hacer spoiler del artículo).
Plotly fue el justo ganador de la comparativa. Hoy en día, está integrado en muchas bibliotecas populares de código abierto como PyCaret o Optuna, como una biblioteca de visualización de referencia.
Aunque falta mucho para que alcance a Matplotlib y Seaborn en términos de uso, pcrecerá mucho más rápido que otros en 2022:

Documentación 📚: https://plotly.com/python/
Concluciones
La ciencia de datos es una industria de rápido crecimiento. Para mantenerse al día de todos los cambios, la comunidad crea nuevas herramientas y bibliotecas mucho más rápido de lo es capaz de aprender las existentes. Eso resultaabrumador para los principiantes. Espero que en esta publicación haya logrado ayudar a concentrar su enfoque en las iniciativas y recursos más prometedores para 2022. Todas las bibliotecas comentadas son adicionales a las principales como Matplotlib, Seaborn, XGBoost, NumPy y Pandas, que ni siquiera es necesario mencionar. ¡Gracias por leer!