Cómo hacer Traducción Automática con RNNs (Red Neuronal Recurrente)
Translation into Spanish of an interesting article by Thomas Tracey, an American engineering & product leader focused on enterprise ML, who shows us here how to build a Recurrent Neural Network step by step.
 23 May, 2022 Building a recurrent Neural Network for Machine Translation
23 May, 2022 Building a recurrent Neural Network for Machine TranslationA free translation by Chema, a Spain-based translator specializing in English to Spanish translations with a focus on technology, machine learning and machine translation.
An original text written by Thomas Tracey, originally published in
https://towardsdatascience.com/language-translation-with-rnns-d84d43b40571
* * *
Cómo crear una red neuronal recurrente que traduzca del Inglés al Francés
Esta publicación explora mi trabajo en el proyecto final del programa Udacity Artificial Intelligence Nanodegree. Mi objetivo es ayudar a otros estudiantes y profesionales que se encuentren en las primeras fases de su desarrollo en el aprendizaje automático (ML) y la inteligencia artificial (IA).
Dicho esto, tenga en cuenta que soy product manager de profesión (no tengo el título de ingeniero o científico de datos). Lo que sigue pretende ser una explicación semi-técnica pero accesible de los conceptos y algoritmos de ML. Si algo de lo que sigue es inexacto o si tiene ud. comentarios constructivos, no dude en contactarme.
Puede encontrar mi repositorio de Github aquí y el repositorio fuente original de Udacity, aquí.
Objetivo del proyecto
En este proyecto construyo una red neuronal profunda como parte de un pipeline de traducción automática. El pipeline acepta texto en Inglés como entrada y devuelve su traducción al Francés. El objetivo es lograr la mayor precisión de traducción posible.
Por qué es importante la Traducción Automática
La capacidad de comunicarse entre sí es una parte fundamental inherente al ser humano. Hay casi 7.000 idiomas diferentes en todo el mundo. A medida que nuestro mundo se vuelve cada vez más conectado, la traducción de idiomas proporciona un puente cultural y económico fundamental entre personas de diferentes países y grupos étnicos. Algunos de los casos de uso más obvios incluyen:
- negocios : comercio internacional, inversiones, contratos, finanzas
- comercio : viajes, compra de bienes y servicios extranjeros, atención al cliente
- medios : acceder a la información a través de la búsqueda, compartir información a través de las redes sociales, localización de contenido y publicidad
- educación : intercambio de ideas, colaboración, traducción de trabajos de investigación
- gobierno : relaciones exteriores, negociación
Para satisfacer estas necesidades, las empresas de tecnología están invirtiendo mucho en la traducción automática. Esta inversión y los avances recientes en el aprendizaje profundo han producido importantes mejoras en la calidad de la traducción. Según Google, cambiar al aprendizaje profundo produjo un aumento del 60% en la precisión de la traducción en comparación con el enfoque basado en frases que se usaba anteriormente en Google Translate. Hoy, Google y Microsoft pueden traducir más de 100 idiomas diferentes y se están acercando a la precisión del nivel humano en muchos de ellos.
Sin embargo, aunque la traducción automática ha progresado mucho, aún no es perfecta. 😬

Enfoque para este proyecto
Para traducir un texto de Inglés a Francés necesitamos construir una red neuronal recurrente (RNN). Antes de sumergirnos en la implementación, primero hagamos una introducción sobre las RNN y por qué son útiles para tareas de NLP.
Descripción general de RNN
Las RNN están diseñadas para tomar secuencias de texto como input, devolver secuencias de texto como output, o ambas cosas. Se denominan recurrentes porque las capas ocultas de la red tienen un bucle en el que el output y el estado de la celda de cada paso de tiempo se convierten en input en el siguiente paso del proceso. Esta recurrencia funciona como una especie de memoria. Permite que la información contextual fluya a través de la red para que los resultados relevantes de los procesos anteriores se puedan aplicar a las operaciones de la red en el siguiente proceso.
Esto es análogo a nuestro procedimiento de lectura. Mientras lee esta publicación, está almacenando información importante de palabras y oraciones anteriores y usándola como contexto para comprender cada palabra y oración nueva.
Otros tipos de redes neuronales no pueden hacer esto (todavía). Imagine que está utilizando una red neuronal convolucional (CNN) para realizar la detección de objetos en una película. Actualmente, no hay forma de que la información de los objetos detectados en escenas anteriores informe la detección de objetos del modelo en la escena actual. Por ejemplo, si se detectaron una sala de audiencias y un juez en una escena anterior, esa información podría ayudar a clasificar correctamente el mazo del juez en la escena actual, en lugar de clasificarlo erróneamente como un martillo o un mazo. Pero las CNN no permiten que este tipo de contexto de serie temporal fluya a través de la red como lo hacen las RNN.
Configuración RNN
Dependiendo del caso de uso, querrá configurar su RNN para manejar entradas y salidas de diversas formas. Para este proyecto, utilizaremos un proceso de muchos a muchos en el que la entrada es una secuencia de palabras en inglés y la salida es una secuencia de palabras en francés (la cuarta desde la izquierda en el siguiente diagrama).
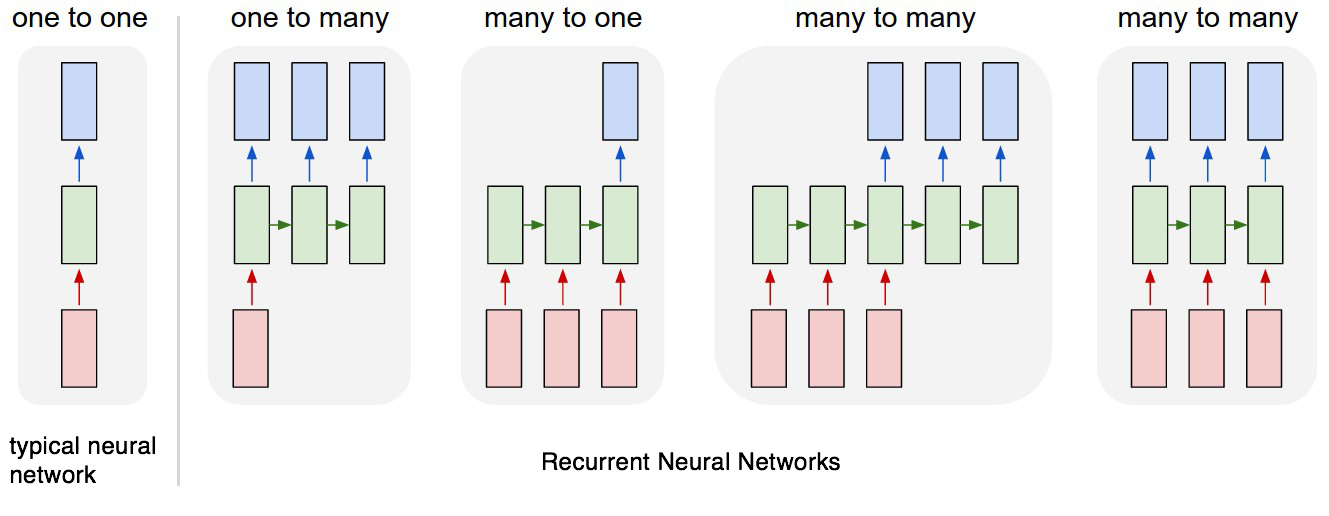
Cada rectángulo es un vector y las flechas representan funciones (por ejemplo, multiplicación de matrices). Los vectores de entrada están en rojo, los vectores de salida están en azul y los vectores verdes mantienen el estado de RNN (más sobre esto pronto).
De izquierda a derecha: (1) Modo de procesamiento estándar sin RNN, desde entrada de tamaño fijo hasta salida de tamaño fijo (por ejemplo, clasificación de imágenes). (2) Salida de secuencia (por ejemplo, el subtítulo de imagen toma una imagen y genera una oración de palabras). (3) Entrada de secuencia (por ejemplo, análisis de sentimiento en el que una oración dada se clasifica como expresión de sentimiento positivo o negativo). (4) Entrada de secuencia y salida de secuencia (por ejemplo, traducción automática: un RNN lee una oración en inglés y luego emite una oración en francés). (5) Entrada y salida de secuencia sincronizada (por ejemplo, clasificación de video donde deseamos etiquetar cada cuadro del video). Tenga en cuenta que en todos los casos no hay restricciones preespecificadas en las secuencias de longitudes porque la transformación recurrente (verde) es fija y se puede aplicar tantas veces como queramos.
— Andrej Karpathy, La eficacia irrazonable de las redes neuronales recurrentes
Construyendo el pipeline
A continuación se muestra un resumen de los diversos pasos de preprocesamiento y modelado. Los pasos de alto nivel incluyen:
- Preprocesamiento : carga y examen de datos, limpieza, tokenización, relleno
- Modelado : construir, entrenar y probar el modelo
- Predicción : genere traducciones específicas del inglés al francés y compare las traducciones de salida con las traducciones de verdad del terreno
- Iteración : iterar sobre el modelo, experimentando con diferentes arquitecturas
Para obtener un tutorial más detallado que incluya el código fuente, consulte el cuaderno de Jupyter Notebook en el repositorio del proyecto .
Frameworks
Usamos Keras para el frontend y TensorFlow para el backend en este proyecto. Prefiero usar Keras sobre TensorFlow porque la sintaxis es más simple, lo que hace que la creación de capas del modelo sea más intuitiva. Sin embargo, hay una compensación con Keras ya que pierde la capacidad de realizar personalizaciones detalladas. Pero esto no afectará los modelos que estamos construyendo en este proyecto.
Preprocesamiento
Cargar y examinar datos
Aquí hay una muestra de los datos. Los inputs son oraciones en Inglés; los outputs son las correspondientes traducciones en Francés.

Cuando ejecutamos un recuento de palabras, podemos ver que el vocabulario para el conjunto de datos es bastante pequeño. Se hizo así para este proyecto, para poder entrenar los modelos en un tiempo razonable.

Limpieza
No es necesario realizar una limpieza adicional en este punto. Los datos ya se convirtieron a minúsculas y se dividieron para que haya espacios entre todas las palabras y la puntuación.
Nota : para otros proyectos de NLP, es posible que deba realizar pasos adicionales como: eliminar etiquetas HTML, eliminar palabras vacías, eliminar puntuación o convertir a representaciones de etiquetas, etiquetar las partes del discurso o realizar la extracción de entidades.
Tokenización
A continuación, necesitamos tokenizar los datos, es decir, convertir el texto a valores numéricos. Esto permite que la red neuronal realice operaciones en los datos de entrada. Para este proyecto, cada palabra y signo de puntuación recibirá una identificación única. (Para otros proyectos de NLP, podría tener sentido asignar a cada personaje una identificación única).
Cuando ejecutamos el tokenizador, crea un índice de palabras, que luego se usa para convertir cada oración en un vector.

Relleno
Cuando alimentamos nuestras secuencias de ID de palabras en el modelo, cada secuencia debe tener la misma longitud. Para lograr esto, se agrega relleno a cualquier secuencia que sea más corta que la longitud máxima (es decir, más corta que la oración más larga).

Codificación One-Hot (no utilizada)
En este proyecto, nuestras secuencias de entrada serán un vector que contiene una serie de números enteros. Cada número entero representa una palabra en inglés (como se ve arriba). Sin embargo, en otros proyectos, a veces se realiza un paso adicional para convertir cada número entero en un vector codificado one-hot. No usamos codificación one-hot (OHE) en este proyecto, pero verá referencias a ella en ciertos diagramas (como el que se muestra a continuación). Simplemente no quería que te confundieras.
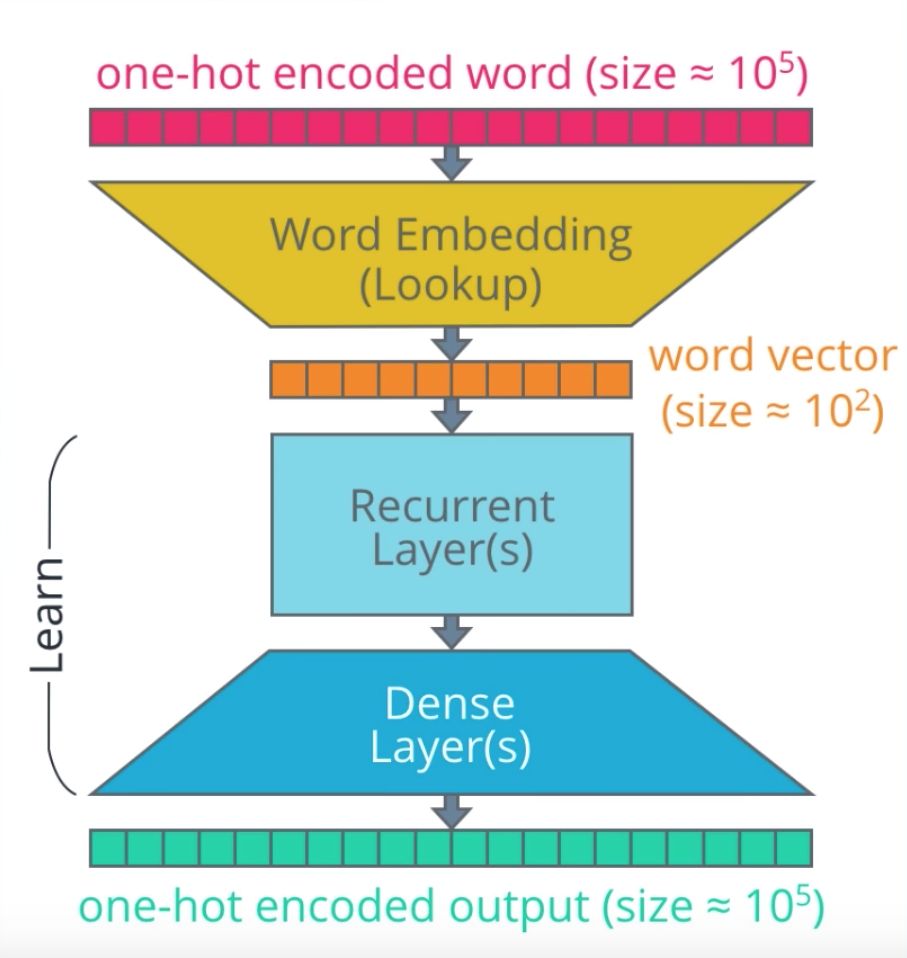
Una de las ventajas de OHE es la eficiencia, ya que puede funcionar a una velocidad de reloj más rápida que otras codificaciones . La otra ventaja es que OHE representa mejor los datos categóricos donde no existe una relación ordinal entre diferentes valores. Por ejemplo, supongamos que clasificamos a los animales como mamíferos, reptiles, peces o aves. Si los codificamos como 1, 2, 3, 4 respectivamente, nuestro modelo puede suponer que existe un orden natural entre ellos, lo cual no existe. No es útil estructurar nuestros datos de manera que los mamíferos estén antes que los reptiles y así sucesivamente. Esto puede inducir a error a nuestro modelo y provocar resultados deficientes. Sin embargo, si luego aplicamos una codificación one-hot a estos enteros, cambiándolos a representaciones binarias (1000, 0100, 0010, 0001 respectivamente), entonces el modelo no puede inferir ninguna relación ordinal.
Pero, uno de los inconvenientes de OHE es que los vectores pueden volverse muy largos y dispersos. La longitud del vector está determinada por el vocabulario, es decir, el número de palabras únicas en su corpus de texto. Como vimos en el paso de examen de datos anterior, nuestro vocabulario para este proyecto es muy pequeño: solo 227 palabras en inglés y 355 palabras en francés. En comparación, el Oxford English Dictionary tiene 172.000 palabras . Pero, si incluimos varios nombres propios, tiempos verbales y argot, podría haber millones de palabras en cada idioma. Por ejemplo, word2vec de Google está entrenado en un vocabulario de 3 millones de palabras únicas. Si usáramos OHE en este vocabulario, el vector para cada palabra incluiría un valor positivo (1) rodeado por 2,999,999 ceros.
Y, dado que estamos usando incrustaciones (en el siguiente paso) para codificar aún más las representaciones de palabras, no necesitamos molestarnos con OHE. Cualquier ganancia de eficiencia no vale la pena en un conjunto de datos tan pequeño.
Modelado
Primero, analicemos la arquitectura de un RNN a un alto nivel. Con referencia al diagrama anterior, hay algunas partes del modelo que debemos tener en cuenta:
- entradas _ Las secuencias de entrada se introducen en el modelo con una palabra para cada paso de tiempo. Cada palabra se codifica como un entero único o un vector codificado en caliente que se asigna al vocabulario del conjunto de datos en inglés.
- Incrustación de capas . Las incrustaciones se utilizan para convertir cada palabra en un vector. El tamaño del vector depende de la complejidad del vocabulario.
- Capas recurrentes (codificador) . Aquí es donde el contexto de los vectores de palabras en pasos de tiempo anteriores se aplica al vector de palabras actual.
- Capas Densas (Decodificador) . Estas son capas típicas totalmente conectadas que se utilizan para decodificar la entrada codificada en la secuencia de traducción correcta.
- Salidas . Los resultados se devuelven como una secuencia de números enteros o vectores codificados en caliente que luego se pueden asignar al vocabulario del conjunto de datos en francés.
Incrustaciones
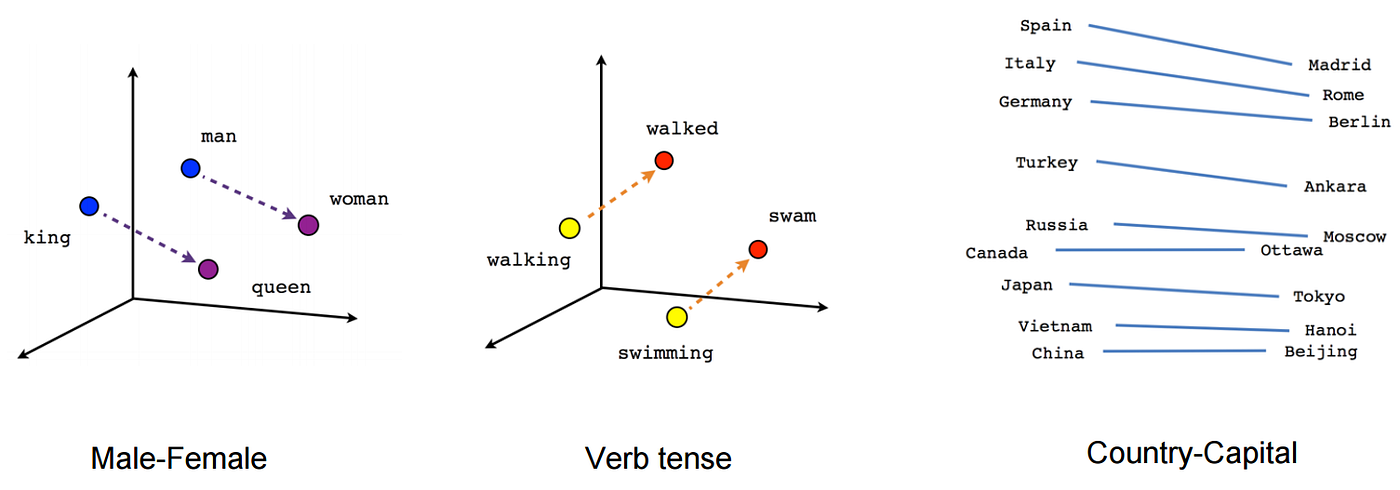
Las incrustaciones nos permiten capturar relaciones de palabras sintácticas y semánticas más precisas. Esto se logra proyectando cada palabra en un espacio n-dimensional. Las palabras con significados similares ocupan regiones similares de este espacio; cuanto más cerca están dos palabras, más similares son. Y, a menudo, los vectores entre palabras representan relaciones útiles, como género, tiempo verbal o incluso relaciones geopolíticas.
El entrenamiento de incrustaciones en un gran conjunto de datos desde cero requiere una gran cantidad de datos y computación. Entonces, en lugar de hacerlo nosotros mismos, normalmente usamos un paquete de incrustaciones previamente entrenado como GloVe o word2vec . Cuando se usan de esta manera, las incrustaciones son una forma de transferencia de aprendizaje . Sin embargo, dado que nuestro conjunto de datos para este proyecto tiene un vocabulario pequeño y una variación sintáctica baja, usaremos Keras para entrenar las incrustaciones nosotros mismos.
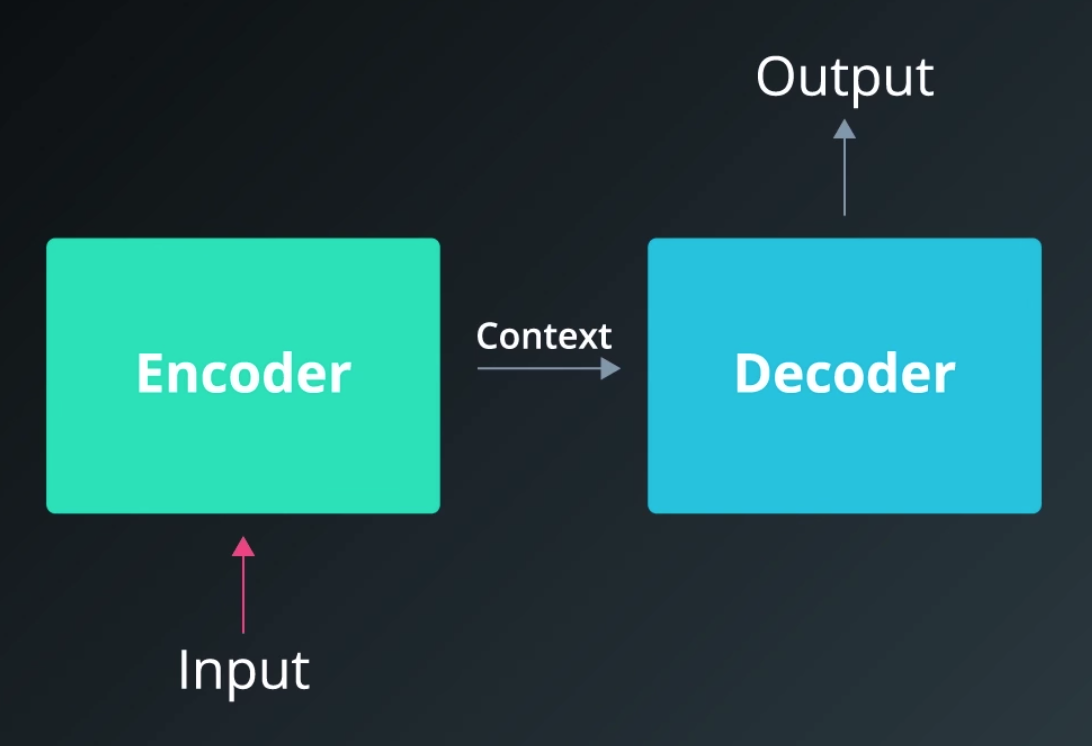
Codificador y decodificador
Nuestro modelo de secuencia a secuencia vincula dos redes recurrentes: un codificador y un decodificador. El codificador resume la entrada en una variable de contexto, también llamada estado. Luego, este contexto se decodifica y se genera la secuencia de salida.
Dado que tanto el codificador como el decodificador son recurrentes, tienen bucles que procesan cada parte de la secuencia en diferentes pasos de tiempo. Para imaginar esto, es mejor desenrollar la red para que podamos ver lo que sucede en cada paso de tiempo.
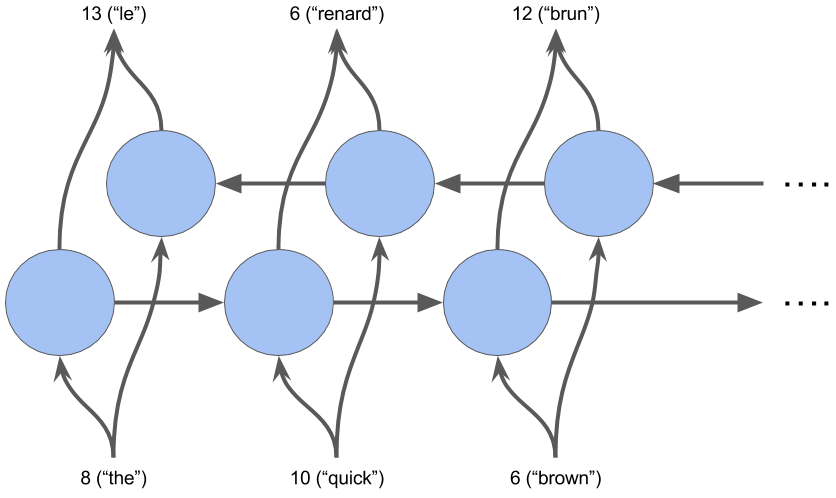
En el siguiente ejemplo, se necesitan cuatro pasos de tiempo para codificar toda la secuencia de entrada. En cada paso de tiempo, el codificador “lee” la palabra de entrada y realiza una transformación en su estado oculto. Luego pasa ese estado oculto al siguiente paso de tiempo. Tenga en cuenta que el estado oculto representa el contexto relevante que fluye a través de la red. Cuanto mayor sea el estado oculto, mayor será la capacidad de aprendizaje del modelo, pero también mayores los requisitos de cálculo. Hablaremos más sobre las transformaciones dentro del estado oculto cuando cubramos las unidades recurrentes cerradas (GRU).
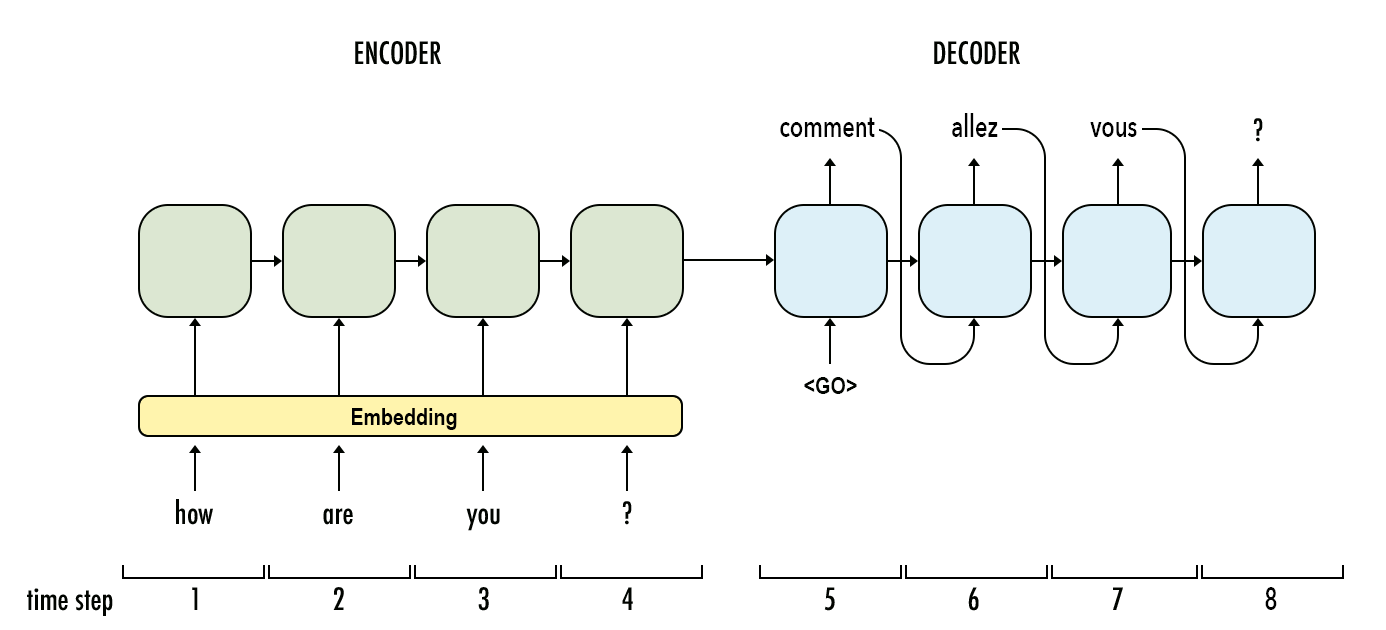
Por ahora, observe que para cada paso de tiempo después de la primera palabra de la secuencia hay dos entradas: el estado oculto y una palabra de la secuencia. Para el codificador, es la siguiente palabra en la secuencia de entrada. Para el decodificador, es la palabra anterior de la secuencia de salida.
Además, recuerde que cuando nos referimos a una “palabra”, en realidad nos referimos a la representación vectorial de la palabra que proviene de la capa de incrustación.
Aquí hay otra forma de visualizar el codificador y el decodificador, excepto con una secuencia de entrada en mandarín.
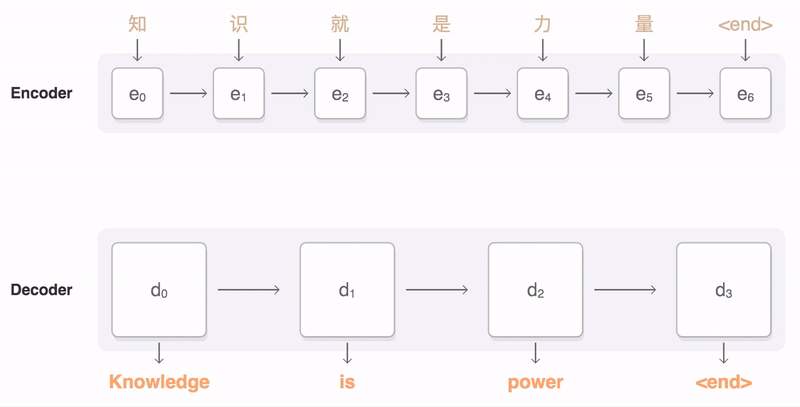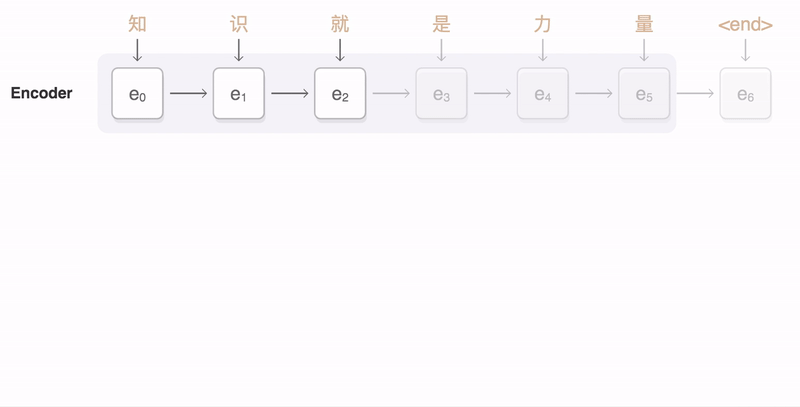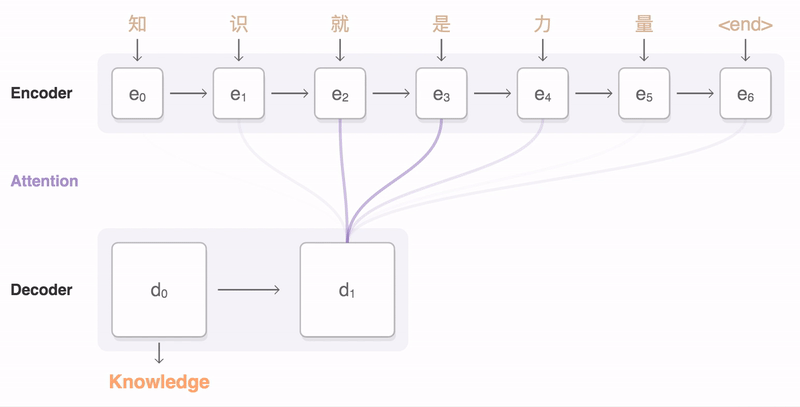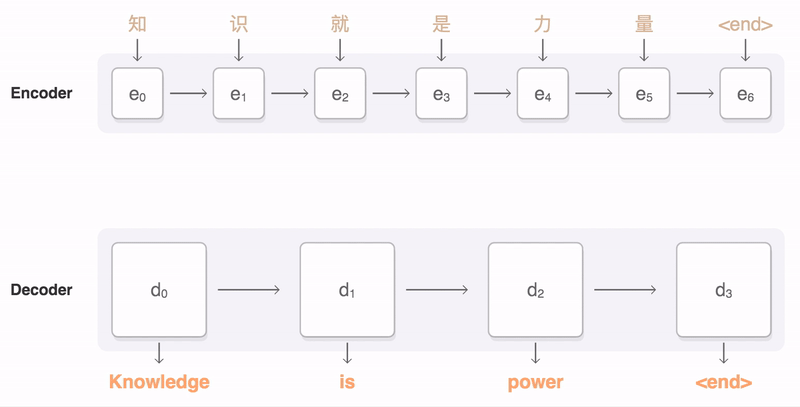
Capa Bidireccional
Ahora que entendemos cómo fluye el contexto a través de la red a través del estado oculto, demos un paso más y permitamos que ese contexto fluya en ambas direcciones. Esto es lo que hace una capa bidireccional.

En el ejemplo anterior, el codificador solo tiene un contexto histórico. Pero proporcionar un contexto futuro puede dar como resultado un mejor rendimiento del modelo. Esto puede parecer contradictorio con la forma en que los humanos procesan el lenguaje, ya que solo leemos en una dirección. Sin embargo, los humanos a menudo requieren un contexto futuro para interpretar lo que se dice. En otras palabras, a veces no entendemos una oración hasta que se proporciona una palabra o frase importante al final. Sucede esto hace cada vez que habla Yoda. 😑 🙏
Para implementar esto, entrenamos dos capas RNN simultáneamente. La primera capa recibe la secuencia de entrada tal cual y la segunda recibe una copia invertida.
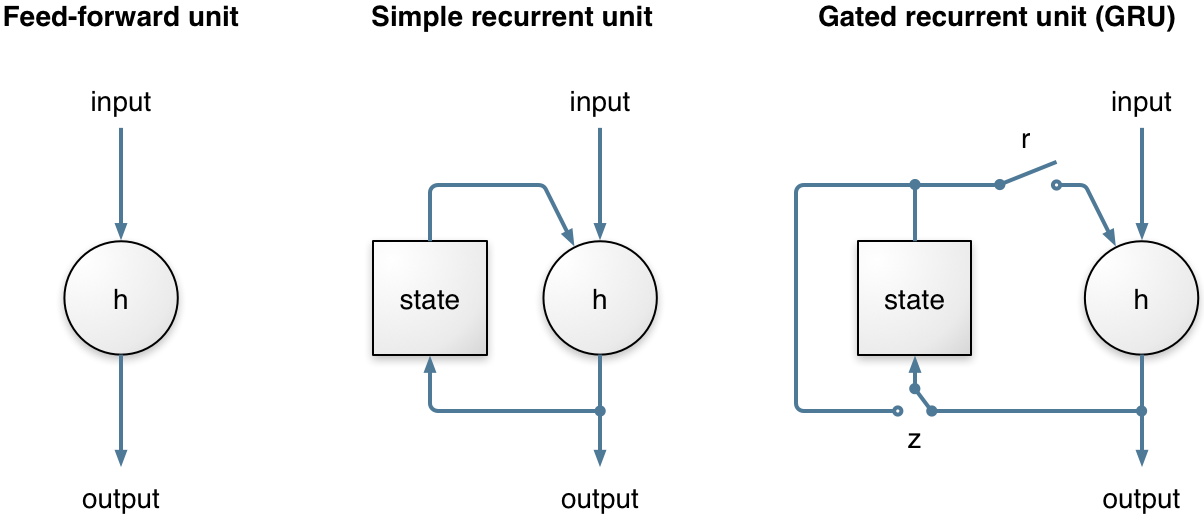
Capa oculta con unidad recurrente cerrada (GRU)
Ahora hagamos nuestro RNN un poco más inteligente. En lugar de permitir que toda la información del estado oculto fluya a través de la red, ¿qué pasaría si pudiéramos ser más selectivos? Tal vez parte de la información sea más relevante, mientras que otra información debería descartarse. Esto es esencialmente lo que hace una unidad recurrente cerrada (GRU).
Hay dos puertas en una GRU: una puerta de actualización y una puerta de reinicio. Este artículo de Simeon Kostadinov explica esto en detalle. En resumen, la puerta de actualización (z) ayuda al modelo a determinar cuánta información de los pasos de tiempo anteriores debe pasar al futuro. Mientras tanto, la puerta de reinicio (r) decide qué cantidad de información pasada olvidar.
Modelo definitivo
Ahora que hemos discutido las diversas partes de nuestro modelo, echemos un vistazo al código. Nuevamente, todo el código fuente está disponible aquí en el cuaderno (versión .html).
def model_final (input_shape, output_sequence_length, english_vocab_size, french_vocab_size):
"""
Build and train a model that incorporates embedding, encoder-decoder, and bidirectional RNN
:param input_shape: Tuple of input shape
:param output_sequence_length: Length of output sequence
:param english_vocab_size: Number of unique English words in the dataset
:param french_vocab_size: Number of unique French words in the dataset
:return: Keras model built, but not trained
"""
# Hyperparameters
learning_rate = 0.003
# Build the layers
model = Sequential()
# Embedding
model.add(Embedding(english_vocab_size, 128, input_length=input_shape[1],
input_shape=input_shape[1:]))
# Encoder
model.add(Bidirectional(GRU(128)))
model.add(RepeatVector(output_sequence_length))
# Decoder
model.add(Bidirectional(GRU(128, return_sequences=True)))
model.add(TimeDistributed(Dense(512, activation='relu')))
model.add(Dropout(0.5))
model.add(TimeDistributed(Dense(french_vocab_size, activation='softmax')))
model.compile(loss=sparse_categorical_crossentropy,
optimizer=Adam(learning_rate),
metrics=['accuracy'])
return mode
Resultados
Los resultados del modelo final se pueden encontrar en la celda 20 del cuaderno.

Precisión de validación: 97,5%
Tiempo de entrenamiento: 23 ciclos
Mejoras futuras
- Realice una división de datos adecuada (entrenamiento, validación, prueba). Actualmente, no hay un conjunto de pruebas, solo entrenamiento y validación. Obviamente, esto no sigue las mejores prácticas.
- LSTM + atención. Esta ha sido la arquitectura de facto para las RNN en los últimos años, aunque existen algunas limitaciones. No usé LSTM porque ya lo había implementado en TensorFlow en otro proyecto y quería experimentar con GRU + Keras para este proyecto.
- Entrene en un corpus de texto más grande y más diverso. El corpus de texto y el vocabulario de este proyecto son bastante pequeños, con poca variación en la sintaxis. Como resultado, el modelo es muy frágil. Para crear un modelo que generalice mejor, deberá entrenar en un conjunto de datos más grande con más variabilidad en la gramática y la estructura de las oraciones.
- Capas residuales. Podría agregar capas residuales a un LSTM RNN profundo, como se describe en este documento. O utilice capas residuales como alternativa a LSTM y GRU, como se describe aquí.
- Incrustaciones. Si está entrenando en un conjunto de datos más grande, definitivamente debe usar un conjunto de incrustaciones previamente entrenado, como word2vec o GloVe. Aún mejor, use ELMo o BERT.
- Modelo de Lenguaje Embebido (ELMo). Uno de los mayores avances en incrustaciones universales en 2018 fue ELMo, desarrollado por el Instituto Allen para IA. Una de las principales ventajas de ELMo es que aborda el problema de la polisemia, en el que una sola palabra tiene múltiples significados. ELMo se basa en el contexto (no en las palabras), por lo que los diferentes significados de una palabra ocupan diferentes vectores dentro del espacio de incrustación. Con GloVe y word2vec, cada palabra tiene solo una representación en el espacio de incrustación. Por ejemplo, la palabra “reina” podría referirse a la matriarca de una familia real, una abeja, una pieza de ajedrez o la banda de rock de la década de 1970. Con las incrustaciones tradicionales, todos estos significados están vinculados a un solo vector para la palabra reina. Con ELMO, estos son cuatro vectores distintos, cada uno con un conjunto único de palabras de contexto que ocupan la misma región del espacio incrustado. Por ejemplo, esperaríamos ver palabras como reina, torre y peón en un espacio vectorial similar relacionado con el juego de ajedrez. Y esperaríamos ver reina, colmena y miel en un espacio vectorial diferente relacionado con las abejas. Esto proporciona un impulso significativo en la codificación semántica.
- Representaciones de Codificador Bidireccional de Transformer (BERT) . En lo que va de 2019, el mayor avance en incrustaciones bidireccionales ha sido BERT, que Google ofreció como
open-source. ¿En qué se diferencia BERT?
Los modelos context-free, como word2vec o GloVe, generan una representación incrustada de una sola palabra para cada palabra del vocabulario. Por ejemplo, la palabra “banco” tendría la misma representación sin contexto en “cuenta de banco” y “banco del parque”. En cambio, los modelos contextuales generan una representación de cada palabra basada en las otras palabras de la oración. Por ejemplo, en la oración “Accedí a la cuenta de mi banco”, un modelo contextual unidireccional representaría “banco” basado en “Accedí a” pero no a “cuenta”. Sin embargo, BERT representa “banco” utilizando tanto su contexto anterior como el siguiente: “Accedí a la… cuenta”, comenzando desde el fondo de una red neuronal profunda, haciéndola profundamente bidireccional.
— Jacob Devlin y Ming-Wei Chang, blog de IA de Google
Contacto
Espero que haya encontrado útil este post. Una vez más, si tiene algún comentario, me encantaría escucharlo. Publique sus opiniones en los comentarios.
Si desea comentar oportunidades profesionales o colaboraciones, puede encontrarme aquí en LinkedIn o ver mi portfolio aquí .