{kind=link}
Translation into Spanish of an interesting article by Kyle Gallatin, software engineer for machine learning infrastructure and delivery at scale.
Los insignes BERT, ELMo y compañía. (Cómo PNL descifró el aprendizaje de transferencia)
Translation into Spanish of an interesting article by Jay Alammar, a brilliant ML research engineer, builder, writter and developper focused on NLP language models and visualization.
bertelmonlptranslation into spanish
2 May, 2022 How NLP cracked transfer learning.
A free translation by Chema, a Spain-based translator specializing in English to Spanish translations, with a growing interest in Machine Learning Models and Machine Translation.
An original text written by Jay Alammar, originally published in
https://jalammar.github.io/illustrated-bert/
* * *
Actualización 2021
Echa un vistazo a esta breve y sencilla introducción en video sobre BERT
El año 2018 ha sido un importante punto de inflexión para los modelos de aprendizaje automático que manejan texto (o, más exactamente, Procesamiento del Lenguaje Natural o PNL para abreviar). Nuestra comprensión conceptual de la mejor forma de representar palabras y oraciones comprendiendo los significados y las relaciones subyacentes está evolucionando rápidamente. Además, la comunidad de NLP ha estado presentando componentes increíblemente poderosos que puedes descargar y usar libremente en tus propios modelos y versiones (lo que se conoce como el momento ImageNet de NLP, en referencia a cómo hace años desarrollos similares aceleraron el desarrollo del aprendizaje automático en tareas de Visión Artificial) .
Uno de los últimos hitos en este desarrollo es el lanzamiento de BERT, un evento descrito como el comienzo de una nueva era en la PNL. BERT es un modelo que rompió varios récords relativos a la forma en la que estos modelos pueden manejar tareas basadas en el lenguaje. Poco después del lanzamiento del documento que presenta Bert, el equipo abrió el código del modelo y puso a libre disposición la descarga de versiones del modelo pre-entrenadas con conjuntos de datos masivos. Este es un desarrollo trascendental, ya que permite a cualquier persona desarrollar un modelo de aprendizaje automático que involucre procesamiento del lenguaje, usando este motor como un componente fácilmente disponible, ahorrando el tiempo, la energía, el conocimiento y los recursos que habría tenido que destinar a entrenar un modelo de procesamiento del lenguaje construido desde cero.
BERT se basa en algunas buenas ideas que han ido surgiendo recientemente en la comunidad de NLP, y que incluyen, entre otros, el aprendizaje semi-supervisado (de Andrew Dai y Quoc Le), ELMo (de Matthew Peters e investigadores de AI2 y UW CSE ), ULMFiT (del fundador de fast.ai Jeremy Howard y Sebastian Ruder), transformer OpenAI (de los investigadores de OpenAI Radford, Narasimhan, Salimans y Sutskever) y los Transformer (de Vaswani et alia.) .
Conviene conocer bien algunos conceptos esenciales para comprender correctamente qué es BERT. Pero comencemos por ver las formas en que puedes usar BERT, antes de ver los conceptos involucrados en el modelo en sí.
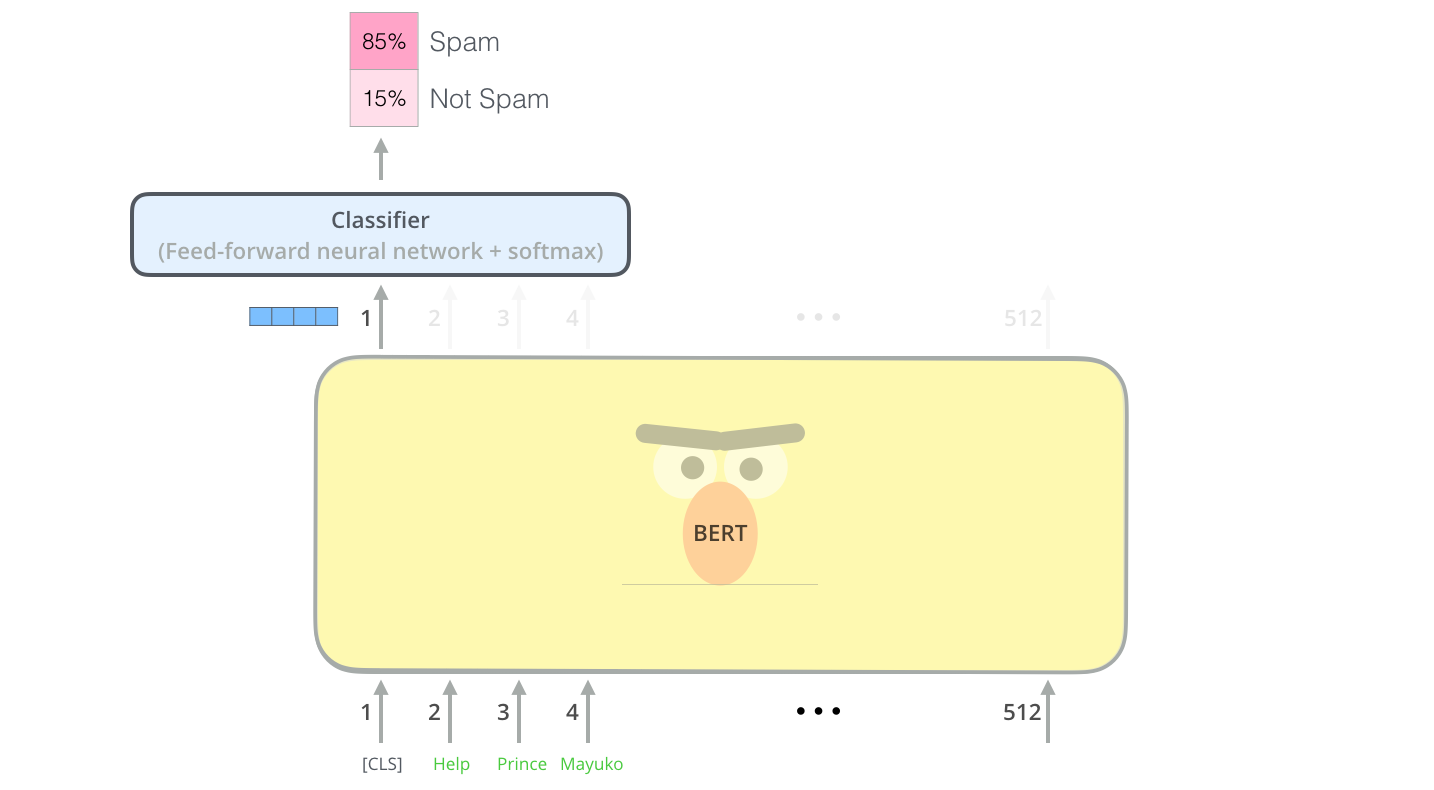
Ejemplo: clasificación de oraciones
La forma más directa de emplear BERT es usarlo para clasificar un fragmento de texto. El modelo tendría este aspecto:
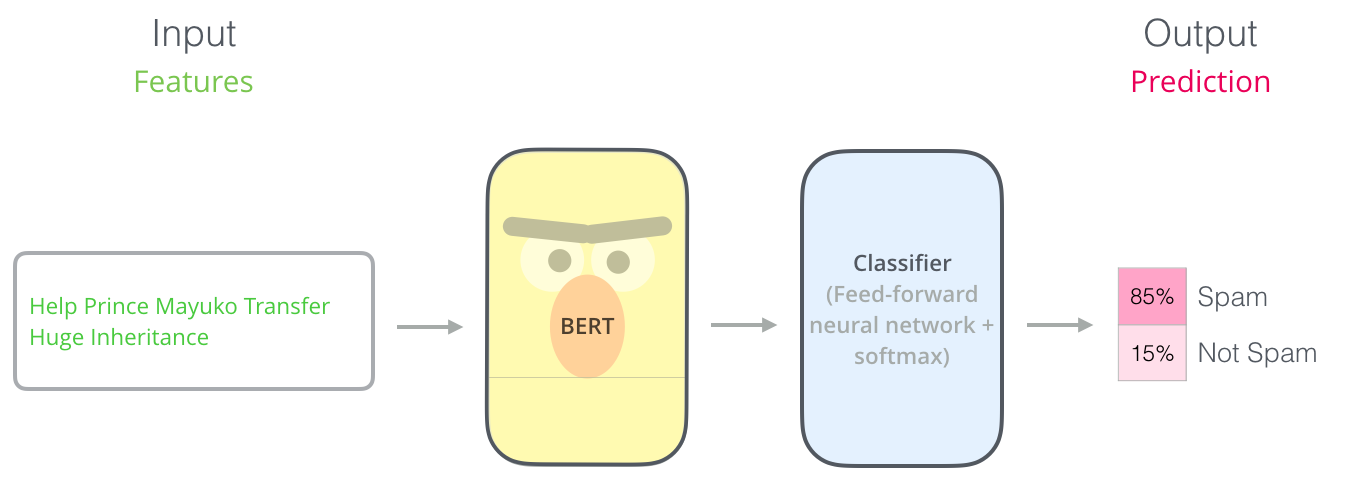
Para entrenar un modelo de este tipo, principalmente se tiene que entrenar el clasificador, con cambios mínimos en el modelo BERT durante la fase de entrenamiento. Este proceso de entrenamiento se llama Ajuste Fino (Fine-Tunning) y tiene sus raíces en el Aprendizaje Secuencial Semi-supervisado y ULMFiT.
Para las personas que no están versadas en el tema, dado que hablamos de clasificadores, estamos en el dominio del aprendizaje supervisado, dentro del campo del aprendizaje automático. Lo que significaría que necesitamos un conjunto de datos etiquetados para entrenar dicho modelo. Para este ejemplo de clasificador de spam, el conjunto de datos etiquetado sería una lista de mensajes de correo electrónico y una etiqueta (“spam” o “no spam” para cada mensaje).

Otros ejemplos de este uso podrían incluir:
- Análisis de sentimientos
- Entrada: Reseña de película/producto. Salida: ¿la revisión es positiva o negativa?
- Conjunto de datos de ejemplo: SST
- Comprobación de hechos
- Entrada: oración. Salida: “Declaración” o “No declaración”
- Ejemplo más ambicioso/futurista:
- Entrada: Declaración. Salida: “Verdadera” o “Falsa”
- Full Fact es una organización que crea herramientas automáticas de verificación de datos y declaraciones para el beneficio del público. Parte de su flujo de trabajo es un clasificador automático que lee artículos de noticias y detecta declaraciones y datos falsos (clasifica los textos como afirmaciones veraces o falsas) que luego pueden verificarse (por humanos de momento, con ML más adelante).
- Video: frases incrustadas y verificación automática de datos: Lev Konstantinovskiy .
Arquitectura del modelo
Ahora que tienes en tu cabeza un ejemplo sobre cómo usar BERT, echemos un vistazo más de cerca a cómo funciona.

El paper original del BERT presenta dos tamaños del modelo:
- BERT BASE: comparable en tamaño al Transformer OpenAI (para comparar rendimiento)
- BERT LARGE: un modelo ridículamente enorme que logró los increíbles resultados reseñados en el paper original
BERT es básicamente una pila de codificadores de transformers entrenados. Este es un buen momento para sugerir que leas mi publicación anterior The Illustrated Transformer, donde explico en profundidad el modelo Transformer, un concepto fundamental para entender BERT y los conceptos que discutiremos a continuación.
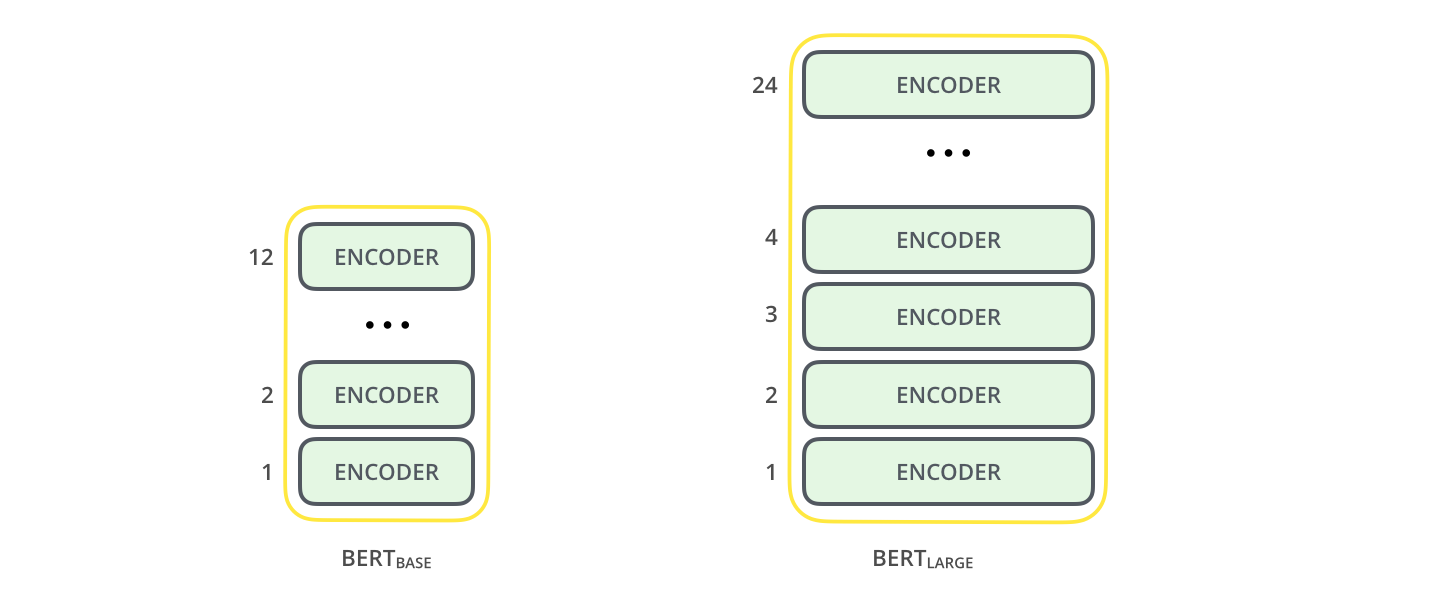
Ambos tamaños de modelos BERT tienen una gran cantidad de capas de codificador (que el documento llama Bloques de transformers): 12 para la versión básica y 24 para la versión grande. Estos también tienen redes feedforward más grandes (768 y 1024 unidades ocultas respectivamente) y más attention heads (12 y 16 respectivamente) que la configuración predeterminada en la implementación de referencia del Transformer en el paper inicial (6 capas de codificador, 512 unidades ocultas, y 8 attention heads).
Entradas del modelo
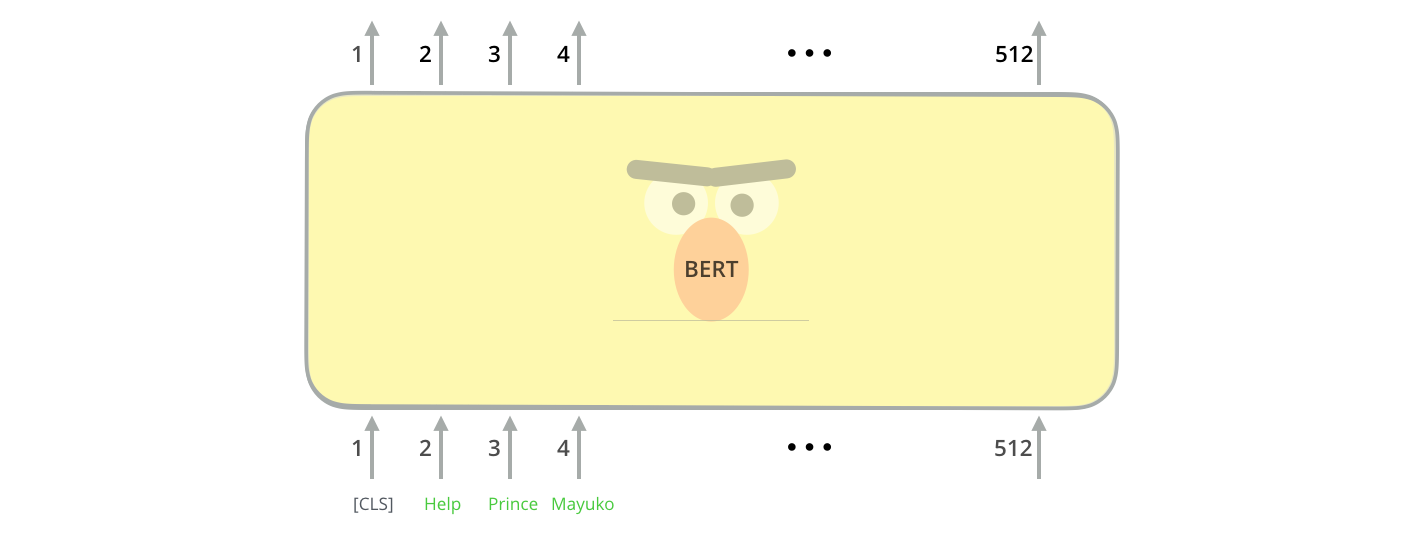
El primer token de entrada viene con un token [CLS] especial por motivos que se aclararán más adelante. CLS aquí significa Clasificación.
Al igual que el codificador Vanilla del transformer, BERT toma una secuencia de palabras como entrada que sigue fluyendo hacia arriba en la pila. Cada capa aplica auto atención, pasa sus resultados a través de una red de avance y luego los devuelve al siguiente codificador.
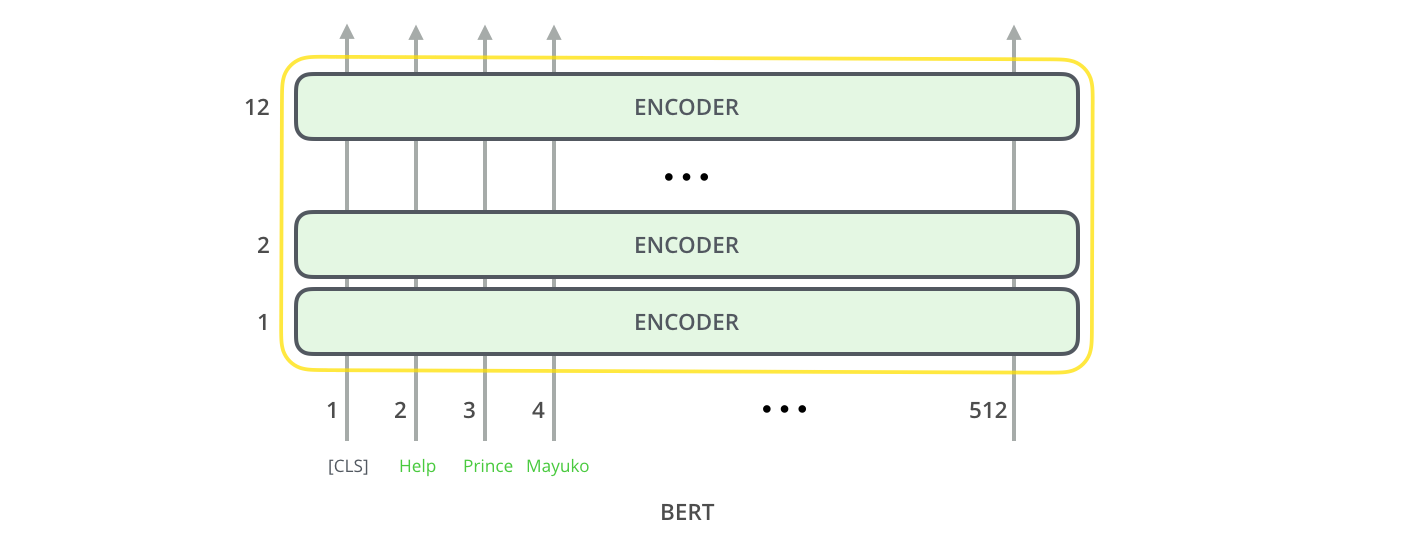
En términos de arquitectura, es idéntica a la del Transformer hasta este punto (aparte del tamaño, que no deja de ser una configuraciones a elección de cada uno). Es en la salida donde empezamos a ver cómo cambian las cosas.
Salidas del modelo
Cada posición genera un vector de tamaño hidden_size (768 en BERT Base). Para el ejemplo de clasificación de oraciones que vimos anteriormente, nos enfocamos en la salida de solo la primera posición (a la que le pasamos el token [CLS] especial).
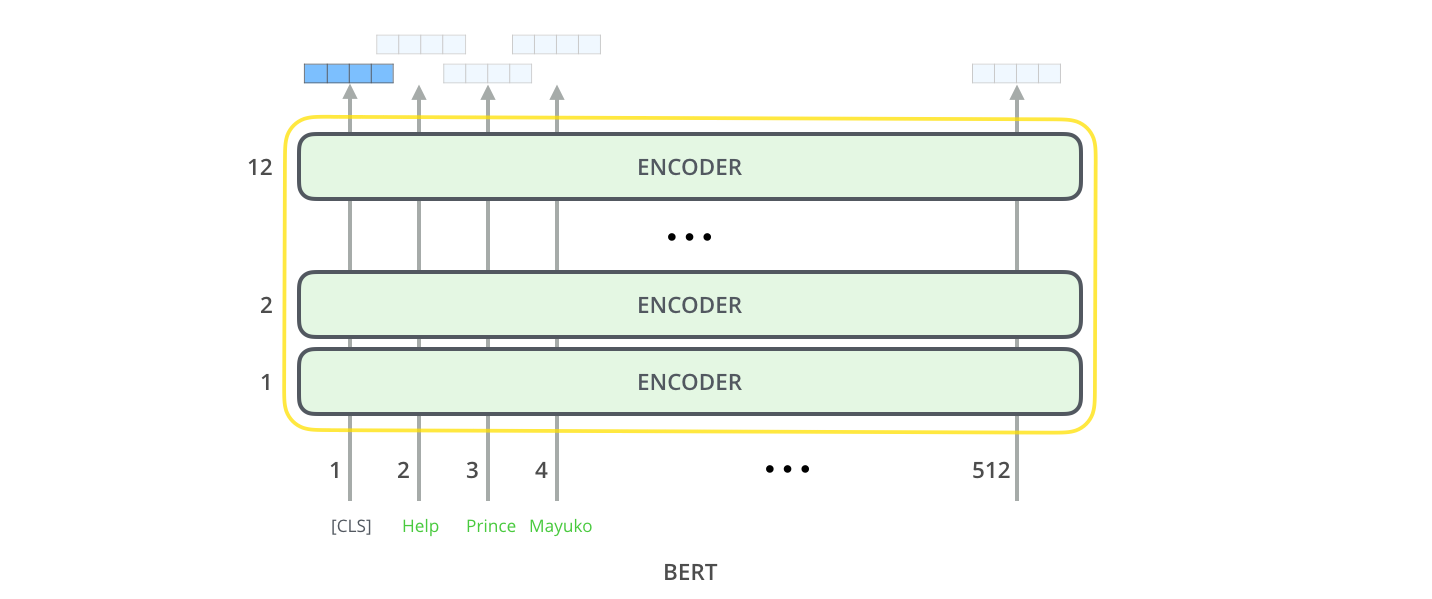
Ese vector ahora se puede usar como entrada para un clasificador de nuestra elección. El documento logra excelentes resultados usando únicamente una red neuronal de una sola capa como clasificador.
Si tienes más etiquetas (por ejemplo, si es un servicio de correo electrónico que etiqueta los correos electrónicos como “spam”, “no spam”, “social” y “promoción”), simplemente modifica la red clasificadora para tener más neuronas de salida que luego pasar por softmax.
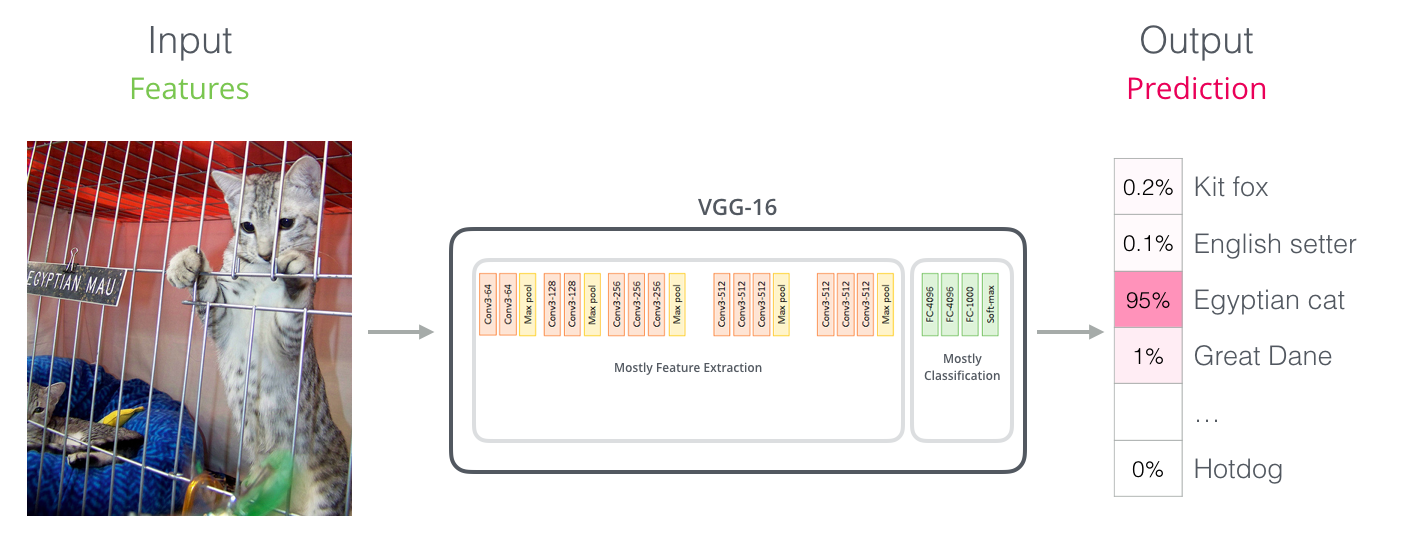
Paralelismos con Redes Convolucionales
Para aquellos con experiencia en visión por computadora, este traspaso de vectores debería recordar lo que sucede entre la parte de convolución de una red como VGGNet y la parte de clasificación totalmente conectada al final de la red.
Una nueva era de integración
Estos nuevos desarrollos traen consigo un nuevo cambio en la forma en que se codifican las palabras. Hasta ahora, las incrustaciones de palabras han sido un motor importante en la forma en que los principales modelos de PNL tratan el lenguaje. Métodos como Word2Vec y Glove se han utilizado ampliamente para este tipo de tareas. Recapitulemos cómo se usan antes de señalar lo que ahora ha cambiado.
Resumen de incrustación de palabras
Para que las palabras sean procesadas por modelos de aprendizaje automático, necesitan alguna forma de representación numérica que los modelos puedan usar en sus cálculos. Word2Vec demostró que podemos usar un vector (una lista de números) para representar correctamente las palabras de una manera que captura las relaciones semánticas o relacionadas con el significado (por ejemplo, la capacidad de saber si las palabras son similares u opuestas, o que un par de palabras como “Estocolmo” y “Suecia” tienen entre ellos la misma relación que tienen entre ellos “El Cairo” y “Egipto”), así como relaciones sintácticas o basadas en la gramática (por ejemplo, la relación entre “tenía” y “tengo” es la mismo que entre “era” y “es”).
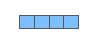
La comunidad rápidamente se dio cuenta de que era mucho mejor idea usar incrustaciones previamente entrenadas con grandes cantidades de datos de texto, en lugar de entrenarlas junto con el modelo en lo que con frecuencia eran pequeños conjuntos de datos. Se pudo así descargar una lista de palabras y sus incrustaciones a partir del entrenamiento previo con Word2Vec o GloVe. Este es un ejemplo de la incrustación GloVe de la palabra “palo” (con un tamaño de vector de incrustación de 200)

Dada su longitud y la gran cantidad de números, en las ilustraciones de mis publicaciones utilizo esta cuadrícula simplificada para representar vectores:
ELMo: el contexto importa
Si estamos usando esta representación GloVe, entonces la palabra “palo” estaría representada por este vector sin importar el contexto. “Espera un minuto”, dijeron varios investigadores de PNL (Peters et. al., 2017 , McCann et. al., 2017 , y una vez más Peters et. al., 2018 en el artículo de ELMo ) , ” palo” tiene múltiples significados dependiendo de dónde se use. ¿Por qué no darle una incrustación basada en el contexto en el que se usa, tanto para capturar el significado de la palabra en ese contexto como para otra información contextual?”. Y así nacieron las incrustaciones de palabras contextualizadas .

Las incrustaciones de palabras contextualizadas pueden dar a las palabras incrustaciones diferentes según el significado que tengan en el contexto de la oración. Además, RIP Robin Williams
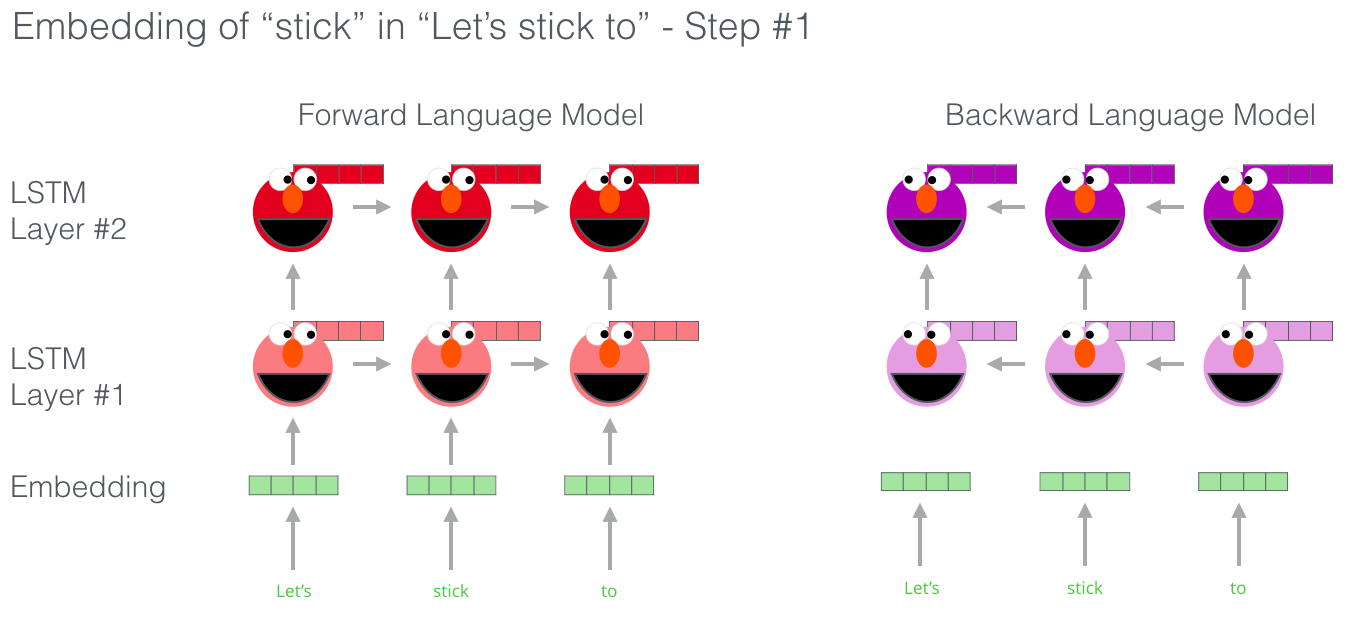
En lugar de usar una incrustación fija para cada palabra, ELMo analiza la oración completa antes de asignarle una incrustación a cada palabra. Utiliza un LSTM bidireccional entrenado en una tarea específica para poder crear esas incrustaciones.
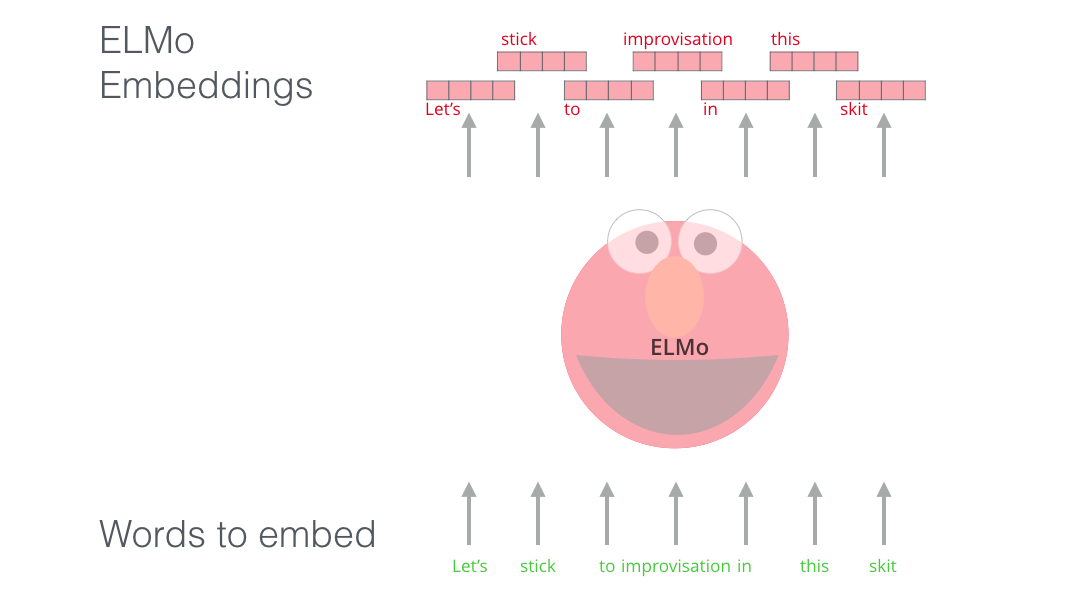
ELMo supuso un paso significativo hacia la formación previa en el contexto de la PNL. El ELMo LSTM se entrenaría en un conjunto de datos masivo en el idioma de nuestro conjunto de datos, y luego podemos usarlo como componente en otros modelos que necesitan manejar el idioma.
¿Cuál es el secreto de ELMo?
ELMo adquirió su comprensión del idioma al ser entrenado para predecir la siguiente palabra en una secuencia de palabras, una tarea llamada Modelado del Lenguaje. Esto es muy interesante porque tenemos grandes cantidades de datos de texto de los que dicho modelo puede aprender sin necesidad de etiquetas.
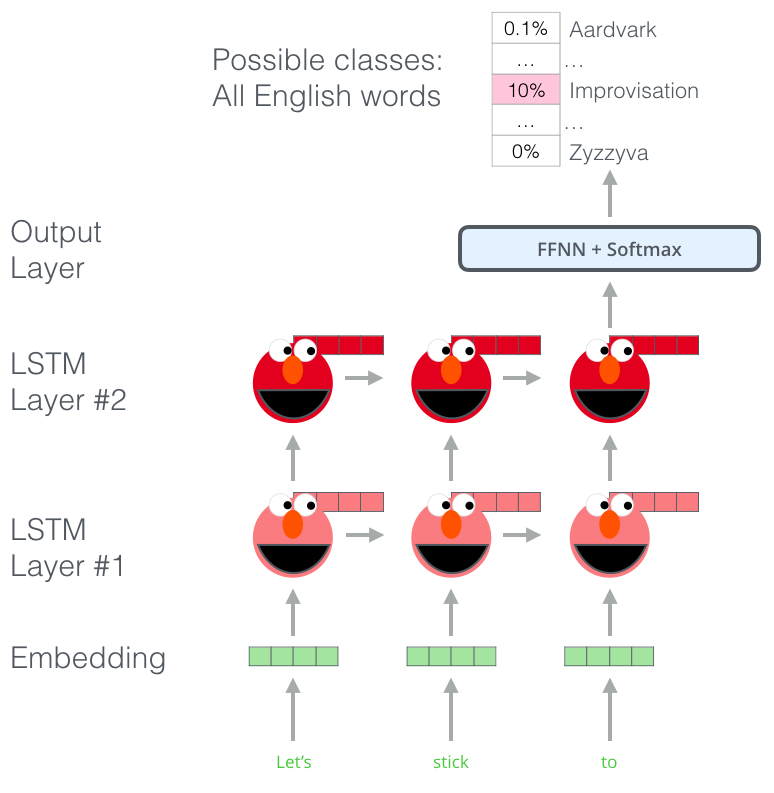
Podemos entrever cada uno de los pasos de LSTM asomando por detrás de la cabeza de ELMo. Resultan muy útiles en el proceso de incrustación después de que realizar este entrenamiento previo.
ELMo en realidad va un paso más allá y entrena un LSTM bidireccional, de modo que su modelo de lenguaje no solo se hace una idea de la palabra siguiente, sino también de la palabra anterior.
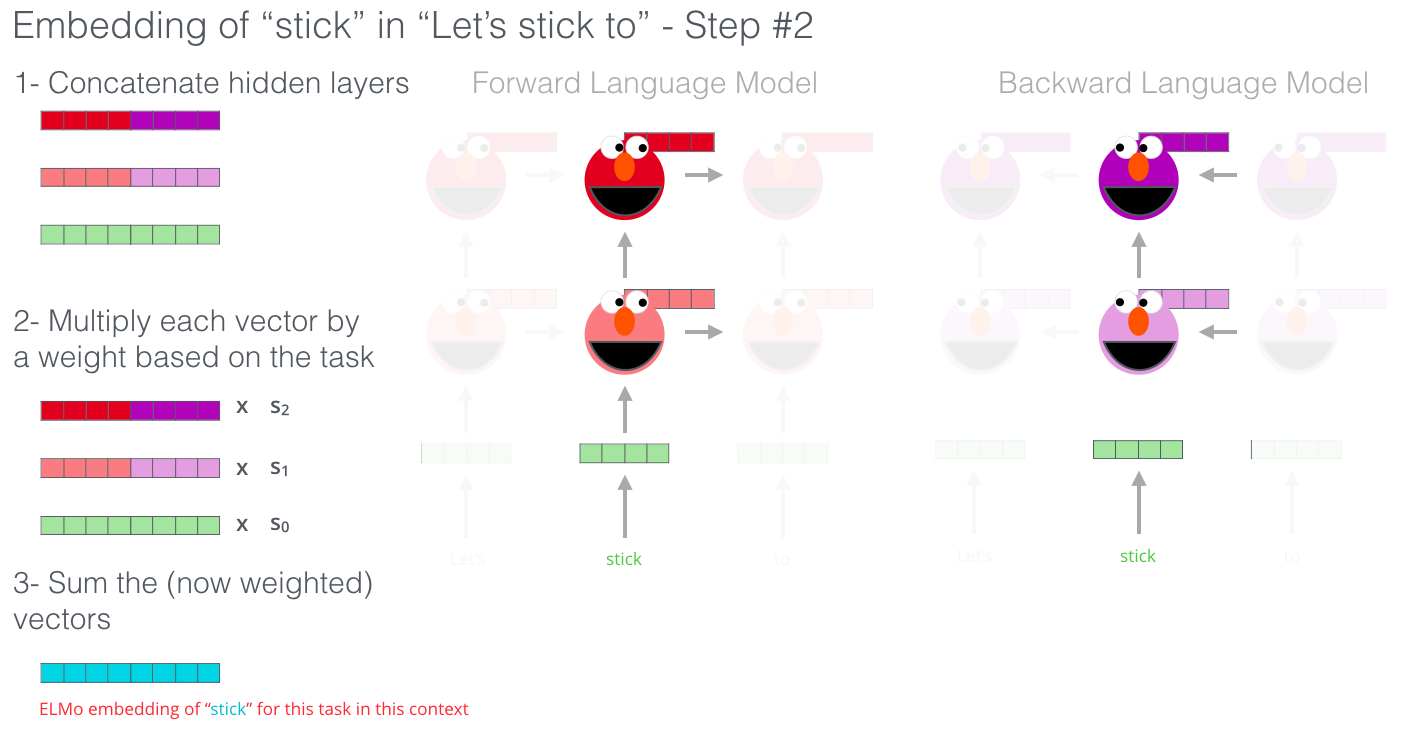
ELMo llega a la incrustación contextualizada mediante la agrupación de los estados ocultos (y la incrustación inicial) de cierta manera (concatenación seguida de suma ponderada).
ULM-FiT: dando en la diana del Aprendizaje de Transferencia en PNL
ULM-FiT introdujo nuevos métodos para utilizar de manera más efectiva mucho de lo que el modelo aprende durante el entrenamiento previo, más allá de las meras incrustaciones e incrustaciones contextualizadas. ULM-FiT introdujo un nuevo modelo de lenguaje y un proceso para ajustar efectivamente ese modelo de lenguaje para resolver varias tareas.
La PNL tuvo por fin una forma de transferir el aprendizaje probablemente tan bien como lo hace la Visión Computerizada.
El Transformer: yendo más allá que los LSTM
El lanzamiento del paper y el código de Transformer, y los resultados que logró en tareas como la traducción automática, comenzaron a hacer que algunos pensaran en ellos como un reemplazo de los LSTM. Esto se vio agravado por el hecho de que los Transformers manejan las dependencias a largo plazo mejor que los LSTM.
La estructura Codificador-Decodificador del Transformer lo hizo perfecto para la traducción automática. Pero, ¿cómo lo usarías para la clasificación de oraciones? ¿Cómo lo usaría para entrenar previamente un modelo de idioma que se puede ajustar para otras tareas (tareas posteriores es lo que el campo llama tareas de aprendizaje supervisado que utilizan un modelo o componente entrenado previamente).
OpenAI Transformer: pre-entrenando un Decodificador de Transformer para Modelado de Lenguaje
Resulta que no necesitamos un Transformer completo para adoptar el aprendizaje por transferencia y un modelo de lenguaje ajustable para tareas de PNL. Podemos hacerlo solo con el decodificador del Transformer. El decodificador es una buena opción porque es una opción natural para el modelado del lenguaje (predecir la siguiente palabra) ya que está diseñado para enmascarar tokens futuros, una característica valiosa cuando genera una traducción palabra por palabra.
El modelo apiló doce capas de decodificador. Dado que no hay codificador en esta configuración, estas capas de decodificador no tendrían la subcapa de atención de codificador-decodificador que tienen las capas de decodificador de Transformer estándar. Sin embargo, todavía tendría la capa de auto atención (enmascarada para que no alcance su punto máximo en tokens futuros).
Con esta estructura, podemos proceder a entrenar el modelo en la misma tarea de modelado de lenguaje: predecir la siguiente palabra utilizando conjuntos de datos masivos (sin etiquetar). ¡Métele 7.000 libros y que aprenda! Los libros son excelentes para este tipo de tareas, ya que permiten que el modelo aprenda a asociar información relacionada, incluso si están separados por mucho texto, algo que no se obtiene, por ejemplo, cuando se entrena con tweets o artículos.
Aprendizaje por transferencia a tareas posteriores
Ahora que el Transformer OpenAI está preentrenado y sus capas se han ajustado para manejar razonablemente el lenguaje, podemos comenzar a usarlo para tareas posteriores. Primero veamos la clasificación de oraciones (clasificar un mensaje de correo electrónico como “spam” o “no spam”):
El documento de OpenAI describe una serie de transformaciones de entrada para manejar las entradas para diferentes tipos de tareas. La siguiente imagen del paper muestra las estructuras de los modelos y las transformaciones de entrada para llevar a cabo diferentes tareas.
BERT: de Decodificadores a Codificadores
El Transformer openAI nos brindó un modelo preentrenado ajustable con precisión basado en el Transformer. Pero faltaba algo en esta transición de LSTM a Transformers. El modelo de lenguaje de ELMo era bidireccional, pero el Transformer openAI solo entrena un modelo de lenguaje directo. ¿Podríamos construir un modelo basado en Transformers cuyo modelo de lenguaje mire tanto hacia adelante como hacia atrás (en la jerga técnica, “esté condicionado tanto en el contexto izquierdo como en el derecho”)?
“Aguántame la cerveza”, dijo BERT -R.
Modelo de lenguaje enmascarado
“Usaremos codificadores de transformer”, dijo BERT.
“Eso es una locura”, respondió Ernie, “Todo el mundo sabe que el condicionamiento bidireccional permitiría que cada palabra se viera indirectamente en un contexto de varias capas”.
“Usaremos máscaras”, sentenció BERT.
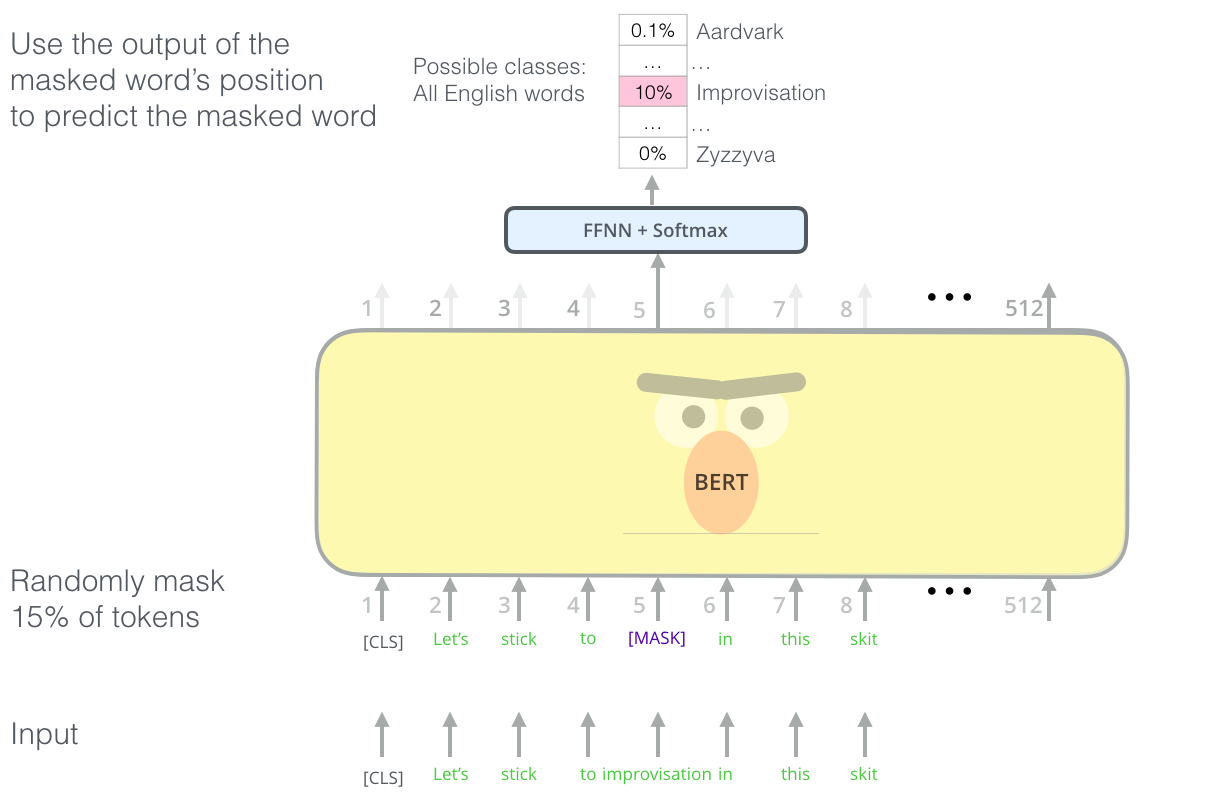
Encontrar la tarea correcta para entrenar una pila de codificadores de Transformer es un obstáculo complejo que BERT resuelve adoptando un concepto de “modelo de lenguaje enmascarado” de la literatura anterior (donde se denomina tarea Cloze).
Más allá de enmascarar el 15% de la entrada, BERT también mezcla un poco las cosas para mejorar la forma en que el modelo se ajusta más tarde. A veces reemplaza aleatoriamente una palabra con otra palabra y le pide al modelo que prediga la palabra correcta en esa posición.
Tareas de dos oraciones
Si miramos atrás en las transformaciones de entrada que hace el Transformer OpenAI para gestionar diferentes tareas, notaremos que algunas tareas requieren que el modelo diga algo inteligente sobre dos oraciones (por ejemplo, ¿son simplemente versiones parafraseadas una de la otra? Dada una entrada de wikipedia como entrada, y una pregunta sobre esa entrada como otra entrada, ¿podemos responder esa pregunta?).
Para hacer que BERT sea mejor en el manejo de relaciones entre múltiples oraciones, el proceso de entrenamiento previo incluye una tarea adicional: dadas dos oraciones (A y B), ¿es probable que B sea la oración que sigue a A, o no?

Modelos específicos de tareas
El paper de BERT muestra varias formas de usar BERT para diferentes tareas.
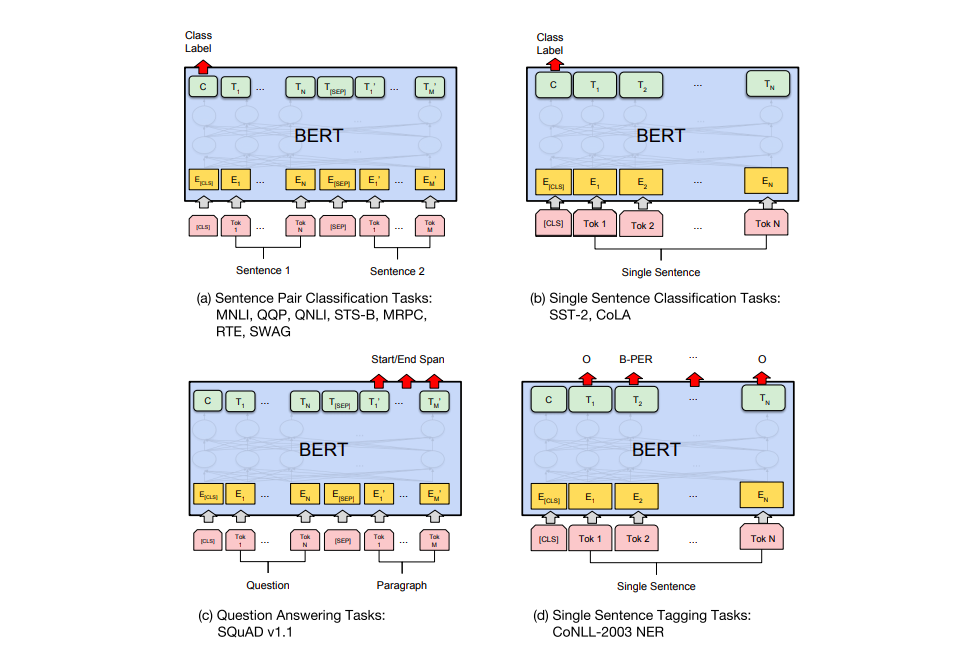
BERT para extracción de características
El enfoque de Ajuste Fino no es la única forma de utilizar BERT. Al igual que ELMo, se puede usar BERT previamente entrenado para crear incrustaciones de palabras contextualizadas. Luego, se puede alimentar estas incrustaciones a un modelo existente, un proceso que el paper muestra que produce resultados no muy lejanos del Ajuste Fino de BERT en tareas como el reconocimiento de entidades.
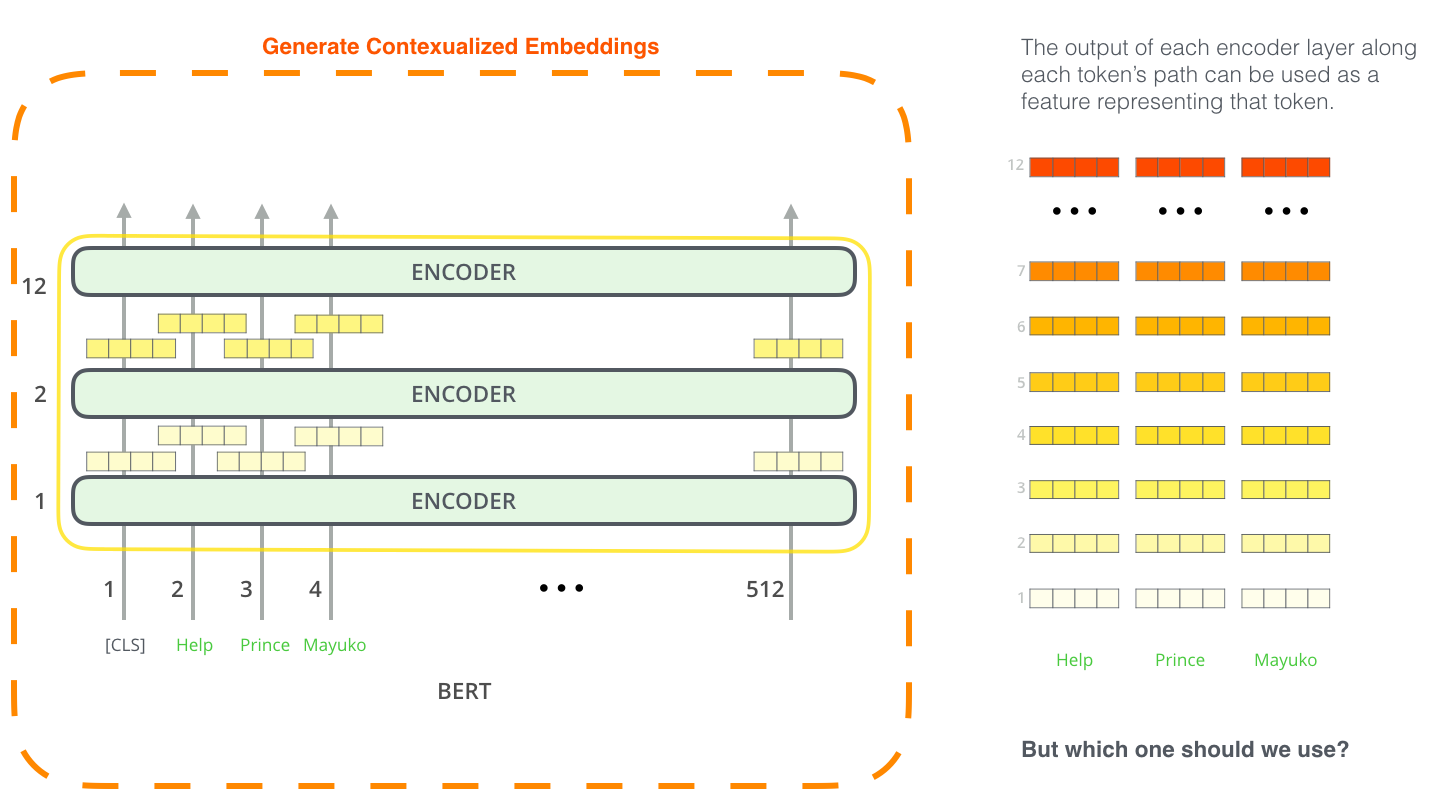
¿Qué vector funciona mejor como incrustación contextualizada? Yo creo que depende de la tarea. El documento examina seis opciones (en comparación con el modelo ajustado que logró una puntuación de 96,4):
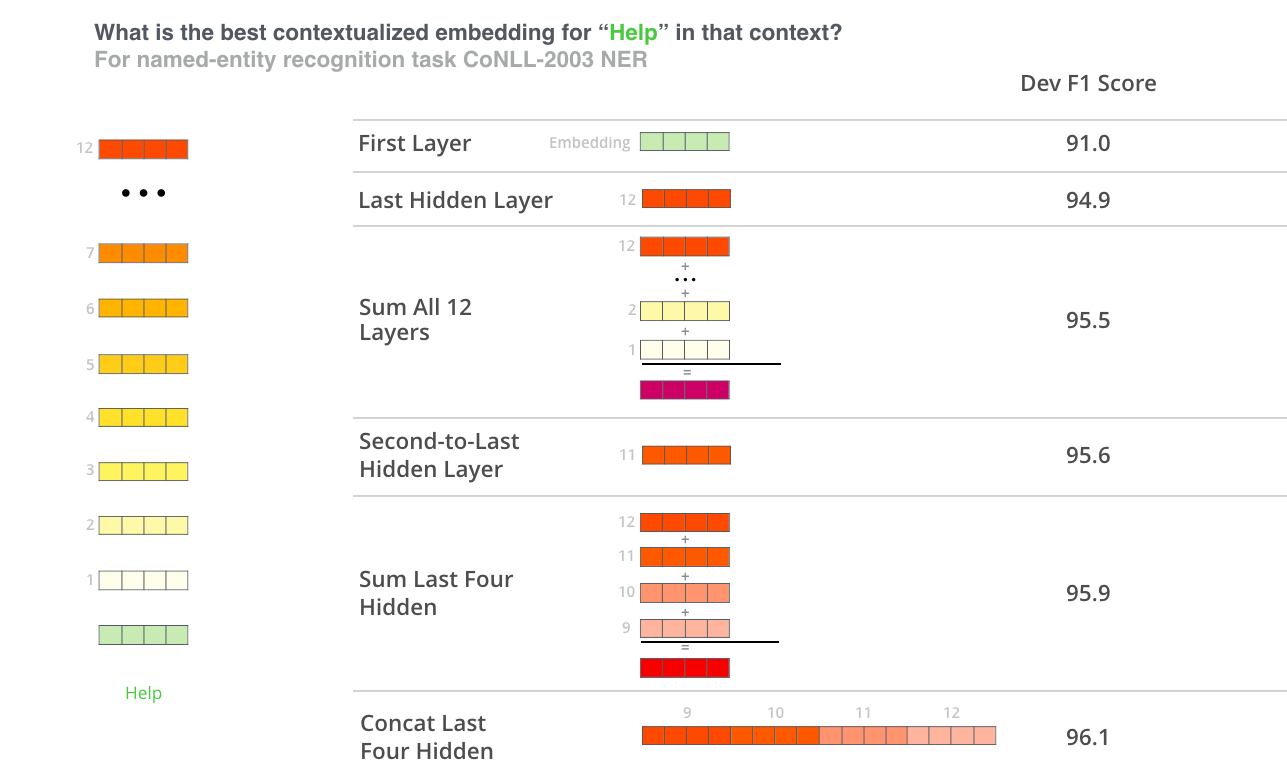
Dale a BERT una vuelta de tuerca
La mejor manera de probar BERT es a través del cuaderno BERT FineTuning con Cloud TPU alojado en Google Colab. Si nunca ha usado Cloud TPU antes, este también es un buen punto de partida, ya que el código BERT también funciona en TPU, CPU y GPU.
El siguiente paso sería mirar el código en el repositorio BERT :
- El modelo está construido en modeling.py (
class BertModel) y es prácticamente idéntico a un codificador Transformer de Vanilla. - run_classifier.py es un ejemplo del proceso de ajuste. También construye la capa de clasificación para el modelo supervisado. Si deseas construir tu propio clasificador, consulta el método
create_model()en ese archivo. - Existen varios modelos preentrenados disponibles para descargar. Incluyen BERT Base y BERT Large, así como idiomas como inglés, chino y un modelo multilingüe que cubre 102 idiomas entrenados en wikipedia.
- BERT no entiende las palabras como fichas, sino más bien como WordPieces. tokenization.py es el tokenizador que puede convertir tus palabras en tokens apropiadas para BERT.
Consulta también la implementación PyTorch de BERT. La biblioteca AllenNLP usa esta implementación para permitir el uso de incrustaciones BERT con cualquier modelo.
Agradecimientos
Gracias a Jacob Devlin , Matt Gardner , Kenton Lee , Mark Neumann y Matthew Peters por brindar sus comentarios sobre los borradores anteriores de esta publicación.
Escrito el 3 de diciembre de 2018
Articulos relacionados

Translation into Spanish of an interesting article by Thomas Tracey, an American engineering & product leader focused on enterprise ML, who shows us here how to build a Recurrent Neural Network step by step.
Translation into Spanish of an interesting article by Devi Parikh Associate Professor @Georgia Tech. Research Director @Meta AI. Co-founded Caliper. Generative artist stateoftheheart.ai.